
Fragile Test
The book has now been published and the content of this chapter has likely changed substanstially.Please see page 239 of xUnit Test Patterns for the latest information.
A test fails to compile or run when the system under test (SUT) is changed in ways that do not affect the part the test is exercising.
Symptoms
We have one or more tests that used to run and pass which either fail to compile and run or fail when they are run. When we have changed the behavior of the SUT in question this change in test results is expected, but when we don't think the change should have affected the tests that are failing or we haven't changed any production code or tests we then have a case of Fragile Test.
Past efforts at automated testing have often run afoul of the "four sensitivities" of automated tests. These sensitivities are what cause Fully Automated Tests (see Goals of Test Automation on page X) that previously passed to suddenly start failing. The root cause for tests failing can be loosely classified into one of these four "sensitivities". Each sensitivity may be cause by a variety of specific test coding behaviors but it is useful to understand the sensitivities in their own right.
Impact
Fragile Tests increase the cost of test maintenance by forcing us to visit many more tests each time we modify the functionality of the system or the fixture. It is particularly deadly on projects that do highly incremental delivery (such as eXtreme Programming.)
Trouble-Shooting Advice
We need to look for patterns in how the tests fail. We ask ourselves "What do all these broken tests have in common?". This should help us understand how the tests are coupled to the SUT. Then we look for ways to minimize this coupling.
The following flowchart summarizes the process for determine which sensitivity we are dealing with:
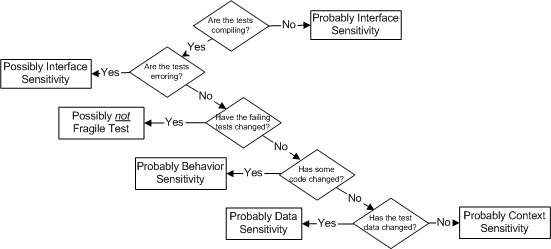
Sketch Fragile Test Trouble-Shooting embedded from Fragile Test Trouble-Shooting.gif
The general sequence is to first ask ourselves whether the tests are failing to compile; if so it is likely Interface Sensitivity. With dynamic languages we may see type incompatibility test errors at run time; this is also a sign of Interface Sensitivity. If the tests are running but the SUT is providing incorrect results we have to ask ourselves whether we have changed the code. If so, we can try backing out the latest code changes to see if that fixes the problem. If that fixes the failing tests (Other tests may fail because we have removed the code that made them pass but at least we have established what code they depend on.) then we had Behavior Sensitivity. If the tests still fail with the latest code changes backed out then something else must have change and we must be dealing with either Data Sensitivity or Context Sensitivity. The former only occurs when we have a Shared Fixture (page X) or we have modified fixture setup code; otherwise we must have a case of Context Sensitivity. While this sequence of asking questions isn't foolproof, it will give the right answer probably nine times out of ten. Caveat Emptor!
Causes
Fragile Tests may be the result of a number of different root causes. They may be a sign of Indirect Testing (see Obscure Test on page X) using the object(s) we modified to access other objects or it could be a sign that we have Eager Tests (see Assertion Roulette on page X) that are verifying too much functionality. They may also be symptoms of over-coupled software that is hard to test in small pieces (Hard-to-Test Code (page X)) or a lack of experience at unit testing using Test Doubles (page X) to test pieces in isolation (Overspecified Software.) Regardless of the root cause, they usually show up as one of the four sensitivities. I'll start by introducing them in a bit more detail and then I'll give some more detailed examples of how the detailed causes.
Cause: Interface Sensitivity
Interface Sensitivity is when a test fails to compile or run because some part of the interface of the SUT that is uses has changed.
Symptoms
In statically typed languages Interface Sensitivity usually shows up as a failure to compile while in dynamically-typed languages Interface Sensitivity only shows up when we run the tests. A test written in a dynamically-typed language may have a test error when it invokes an application programming interface (API) that has been modified (method name change or method signature change) or a test may fail to find a user interface element it needs to interact with the SUT via a user interface. Recorded Tests (page X) that interact with the SUT through a user interface (often called "screen scraping") are particularly prone to this problem.
Possible Solution
The cause of the failures is usually reasonably apparent. The point at which the test fails (to compile or execute) will usually point out the location of the problem. It is rare for the test to continue to run beyond the point of change because it is the change itself that causes the test error.
When the interface is used only internally (within the organization or application) and by automated tests, SUT API Encapsulation (see Test Utility Method on page X) is the best solution for Interface Sensitivity as it reduces the cost and impact of changes to the API and therefore does not discourage necessary changes from being made. A common way to implement SUT API Encapsulation is through the definition of a Higher Level Language (see Principles of Test Automation on page X) that is used to express the tests. The verbs in the test language are then translated into the appropriate method calls by the encapsulation layer which is then the only software that needs to be modified when the interface is modified in somewhat backwards-compatible ways. The "test language" can be implemented in the form of Test Utility Methods such as Creation Methods (page X) and Verification Methods (see Custom Assertion on page X) that hide the API of the SUT from the test.
The only other real alternative for avoiding Interface Sensitivity is to put the interface under strict change control. When the clients of the interface are external and anonymous (such as the clients of Windows (TM) DLLs), this may be the only alternative. In these cases, there is usually a protocol around making changes to interfaces; all changes must be backwards compatible, before older versions of methods can be removed they must be deprecated and deprecated methods must exist for a minimum number of releases or elapsed time.
Cause: Behavior Sensitivity
Behavior Sensitivity is when changes to the SUT cause other tests to fail.
Symptoms
A test that used to pass suddenly starts failing when a new feature is added to the SUT or a bug is fixed. These are both possibly symptoms of Behavior Sensitivity.
Root Cause
Tests may be failing because the functionality they are verifying has been modified. This is not a case of Behavior Sensitivity because it is the whole reason for having regression tests. It is a case of Behavior Sensitivity if:
- the functionality they use to set up the pre-test state of the SUT has been modified,
- the functionality they use to verify the post-test state of the SUT has been modified, or
- the code they use to tear down the fixture has been changed.
If the code that changed is not part of the SUT we are verifying then we are dealing with Context Sensitivity. That is, we may be testing too large a SUT and what we really need to do is to separate it into the part we are verifying and the components on which it depends.
Possible Solution
Any newly incorrect assumptions about the behavior of the SUT used during fixture setup may be encapsulated behind Creation Methods. Similarly, assumptions about the details of post-test state of the SUT can be encapsulated in Custom Assertions or Verification Methods. While these won't eliminate the need to update test code when these assumptions change, they certainly reduce the amount of test code that needs to be changed.
Cause: Data Sensitivity
Data Sensitivity occurs when a test fails because the data being used to test the SUT has been modified. It most commonly occurs when the contents of the test database is changed.
Symptoms
A test that used to pass suddenly starts failing when:
- additional data is added to the repository (database) that holds the pre-test state the SUT,
- records in the repository are modified or deleted,
- the code that sets up a Standard Fixture (page X) is modified, or
- a Shared Fixture is modified before the first test that uses it.
These are all possible symptoms of Data Sensitivity. In all cases, we must be using a Standard Fixture which may be either a shared database or some sort of Shared Fixture such as a Prebuilt Fixture (see Shared Fixture).
Root Cause
Tests may fail because the result verification logic in the test is looking for data that no longer exists in the repository or is using search criteria that accidently includes newly added records. Another cause of failure is that the SUT is being exercised with inputs that reference missing or modified data and therefore it behaves differently.
In all cases, the tests are making assumptions about what data does and does not exist in the database and those assumptions have been violated.
Possible Solution
In those cases where the failures occur during the exercise SUT phase of the test, we need to look at the preconditions of the logic we are exercising and make sure these have not been affected by recent changes to the database.
In most cases, the failures occur during result verification. We need to examine their result verification logic to ensure that it does not make any unreasonable assumptions about what data exists. If it does, we can modify the verification logic.
The failure can occur in the result verification logic even if the problem is that the inputs of the SUT refer to non-existent or modified data. This may require examining the "after" state of the SUT (which differs from the expected) and tracing it back to why it differs from expected. This should expose the mismatch between SUT inputs and the data that existed before the test started executing.
The best solution to Data Sensitivity is to make the tests independent of the
existing contents of the database. This is known as a Fresh Fixture (page X). If this is not possible, we can try using some sort
of Database Partitioning Scheme (see Database Sandbox on page X) to ensure that data
modified for one test does not overlap with the data used by other tests.
(See the sidebar Why Do We Need 100 Customers? (page X)
Include the sidebar 'Why Do We Need 100 Customers?' on opposite page.
for an
example of this.) Another solution is to use to verify that the right
changes have been made to the data. The Delta Assertions (page X)
compare before and after "snapshots" of the data thereby ignoring data
that hasn't changed; this removes the need to hard-code knowledge about
the entire fixture into the result verification phase of the
test.
Cause: Context Sensitivity
Context Sensitivity occurs when a test fails because the state or behavior of the context in which the SUT executes has changed in some way.
Symptoms
A test that used to pass suddenly starts failing for mysterious reasons. Unlike an Erratic Test (page X), the test has consistent results when run repeatedly in a short space of time. What is different is that it now consistently fails regardless of how it is run.
Root Cause
Tests may fail because:
- the functionality they are verifying depends in some way on the time or date.
- The behavior of some other code or system(s) on which the SUT depends has changed
A great source of Context Sensitivity is confusion about what SUT we are intending to verify. Recall that the SUT is whatever piece of software we are intending to verify. When unit testing, this should be a very small part of the overall system or application. Failure to isolate the specific unit (e.g. class or method) is bound to lead to Context Sensitivity because we end up testing too much software all at once. Indirect inputs that should be controlled by the test are thus left to chance and when someone modifies a depended-on component (DOC) our tests fail.
To eliminate Context Sensitivity we need to track down which indirect input to the SUT has changed and why. If the system contains any date or time-related logic, we should look at this logic to see if the length of the month or other similar factors could be the cause of the problem.
If the SUT depends on input from any other systems, we should examine these inputs to see if anything has changed recently. Logs of previous interactions with these other systems are very useful for comparison with logs of the failure scenarios.
If the problem comes and goes, look for patterns of when it passes and when it fails. See Erratic Test for a more detailed discussion of possible causes.
Possible Solution
We need to control all the inputs of the SUT if our tests are to be deterministic. If we depend on inputs from other systems, these inputs may need to be controlled using a Test Stub (page X) that is configured and installed by the test. If the system contains any time/date-specific logic, we need to be able to control the system clock as part of our testing. This may necessitate stubbing out the system clock with a Virtual Clock[VCTP] that gives the test a way to set the starting time/date and possibly to simulate the passage of time.
Cause: Overspecified Software
Also known as: Overcoupled Test
A test says too much about how the software should be structured or behave. This is a form of Behavior Sensitivity (see Fragile Test on page X) associated with a style of testing I call Behavior Verification (page X). It is characterized by the extensive use of Mock Objects (page X) to build layer-crossing tests. The main issues is that the tests describe how the software should do something, not what it should achieve. That is, the tests will only pass if the software is implemented a particular way. It can be avoided by applying the principle Use the Front Door First (see Principles of Test Automation) whenever possible to avoid encoding too much knowledge about the implementation of the SUT into the tests.
Cause: Sensitive Equality
Objects to be verified are converted to strings and compared with an expected string. This is an example of Behavior Sensitivity in that the test is sensitive to behavior that it is not in the business of verifying. We could also think of it as a case of Interface Sensitivity where it is the semantics of the interface that have changed. Either way, the problem is with the way the test was coded; using the string representation of objects for verifying them against expected values is just plain wrong.
Cause: Fragile Fixture
When a Standard Fixture is modified to accommodate a new test, several other tests fail. This is an alias for either Data Sensitivity or Context Sensitivity.
Further Reading
Sensitive Equality and Fragile Fixture were first described in [RTC] which was the first paper published on test smells and refactoring test code. The four sensitivities were first described in [ARTRP] which also described several ways to avoid Fragile Test in Recorded Tests.Copyright © 2003-2008 Gerard Meszaros all rights reserved