
Result Verification
The book has now been published and the content of this chapter has likely changed substanstially.About This Chapter
In the last two chapters, Transient Fixture Management and Persistent Fixture Management I described how to set up the test fixture and to tear it down after exercising the system under test (SUT). In this chapter I introduce the various options for verifying that the SUT has behaved correctly. This includes exercising the SUT and comparing the actual outcome with the expected.Making Tests Self-Checking
One of the key characteristics of tests automated using xUnit is that they can be (and usually are) Self-Checking Tests (see Goals of Test Automation on page X). This is what makes them cost effective enough to be run very frequently. Most members of the xUnit family come with a collection of built-in Assertion Methods (page X) and some documentation that tells us which one to use when. On the surface this sounds pretty simple but there's a lot more to writing good tests than just calling the built-in Assertion Methods. We also need to learn key techniques for making tests easy to understand and for avoiding and removing Test Code Duplication (page X).
A key challenge in coding the assertions is getting access to the information we want to compare with the expected results. This is where observation points come into play; they are what gives us visibility of the state or behavior of the SUT so that we can pass it to the Assertion Methods. Observation points for information accessible via synchronous method calls are pretty straight forward; observation points for other kinds of information can be quite challenging and this is what makes automated unit testing so interesting.
Assertions are usually called from within the Test Method (page X) body right after the SUT has been exercised but this isn't always the case. Some test automaters put assertions after the fixture setup phase of the test to ensure that the fixture is set up correctly. Personally, I think this almost always contributes to Obscure Test (page X) and would rather see us write unit tests for our Test Utility Methods (page X). (The one exception is when we must use a Shared Fixture (page X); it may be worthwhile to use a Guard Assertion (page X) to document what the test requires from it and to fail the test if the fixture is corrupted. We could also do this from within our Finder Methods (see Test Utility Method) that we use to retrieve the objects in the Shared Fixture (page X) that we will use in our tests.) Some styles of testing do require us to set up our expectations before we exercise the SUT; I'll talk about this more in the Using Test Doubles narrative. We'll see several examples of calling Assertion Methods from within Test Utility Methods in this chapter.
One possible though rarely used place to put calls to Assertion Methods is in the tearDown method used in Implicit Teardown (page X). Since this method is run for every test whether it passed or failed (as long as the setUp method succeeded), one can put assertions here. It is the same tradeoff as using Implicit Setup (page X) for building our test fixture; it's less visible but automatically done. See the sidebar Using Delta Assertions to Detect Data Leakage (page X) for an example of putting assertions in the tearDown method used by Implicit Teardown of a superclass to detect when tests were leaving leftover test objects in the database.
Verify State or Behavior?
Ultimately, test automation is about verifying the behavior of the SUT. Some aspects of the SUT's behavior can be verified directly; the value returned by a function is a good example of this. Other aspects of the behavior are more easily verified indirectly by looking at the state of some object. There are two different ways we can verify the actual behavior of the SUT in our tests. We can verify that state of various objects affected by the SUT by extracting that state using an observation point and using assertions to compare it to the expected state. Or we can verify the behavior of the SUT directly by using observation points between the SUT and its depended-on component (DOC) to monitor its interactions (in the form of the method calls it makes) and comparing those method calls with what we expected. State Verification (page X) is done using assertions and since it is the simpler of the two approaches, I will deal with it first. Behavior Verification (page X) is more complicated and builds on the assertion techniques we use for verifying state.
State Verification
The "normal" way to verify the expected outcome has occured is called State Verification. First, we exercise the SUT and then we examine the post-exercise state of the SUT using assertions. We may also examine anything returned by the SUT as a result of the method call we made to exercise it. What is most notable is what we do not do: we do not instrument the SUT in any way to detect how it interacts with other components of the system. That is, we only inspect direct outputs and we only use direct method calls as our observation points.
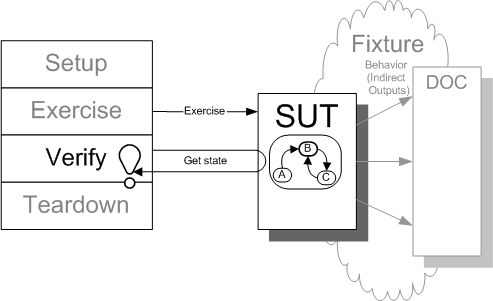
Sketch State Verification embedded from State Verification.gif
Fig. X: State Verification.
In State Verification we assert that the SUT, and any objects it returns, are in the expected state after we have exercised the SUT. We "pay no attention to the man behind the curtain."
State Verification can be done in two slightly different ways. Procedural State Verification (see State Verification) involves writing a sequence of assertions that pick apart the end state of the SUT and verify that it is as expected. Expected Object (see State Verification) is a way of describing the expected state in a way that can be compared with a single Assertion Method call thus reducing Test Code Duplication and increasing test clarity. (More on this later in this chapter.) Either way, we can use either "built-in" assertions or Custom Assertions (page X).
Using Built in Assertions
We use the assertions provided by our testing framework to specify what should be and depend on them to tell us when it isn't so! But simply using the built-in assertions is only a small part of the story.
The simplest form of result verification is the assertion in which we specify what should be true. Most members of the xUnit family support a range of different Assertion Methods including:
- Stated Outcome Assertions (see Assertion Method) such as assertTrue( aBooleanExpression),
- simple Equality Assertions such as assertEquals(expected, actual) and
- Fuzzy Equality Assertions such as assertEquals(expected, actual, tolerance) used for comparing floats.
Of course, the test programming language has some influence on the nature of the assertions. In JUnit, SUnit, CppUnit, NUnit and CsUnit, most of the Equality Assertions take a pair of Objects as their parameters. In C, we don't have objects so in CUnit we cannot compare objects, only values.
There are several things to consider when using Assertion Methods. Naturally, the first priority is the verification of all things that should be true. The better our assertions, the finer our Safety Net (see Goals of Test Automation) and the better will be our confidence level in our code. The second one is the documentation value of the assertions. We want each test to make it very clear that "When the system is in state S1, and I do X, the result should be R and the system should be in state S2". We put the system into state S in our fixture setup logic. "I do X" corresponds to the exercise SUT phase of the test. And "the result is R" and "the system is in state S2" are implemented using assertions. So we want to write our assertions in such a way that they succinctly describe "R" and "S2".
Another thing to consider is that when the test fails, we want the failure message to tell us enough to be able to determine what the problem was. (In his book [TDD-APG] Dave Astels claims he never/rarely used the Eclipse Debugger while writing the code samples because the assertions always told him enough about what was wrong. This is what we strive for!) Therefore, we should almost always include an Assertion Message (page X) as the optional message parameter (assuming our xUnit family member has one!) It avoids us playing Assertion Roulette (page X) in which we cannot even tell which assertion is failing without running the test interactively; this makes fixing Integration Build[SCM] failures much easier to reproduce and fix. It also makes trouble-shooting broken tests easier by telling us what should have happened; the actual outcome tells us what did happen!
When using a Stated Outcome Assertion (such as JUnit's assertTrue) the failure messages tend to be pretty unhelpful (e.g. "Assertion failed"!) We can make the assertion output much more useful by using an Argument Describing Message (see Assertion Message) constructed by incorporating useful bits of data into the message. A good start is to include each of the values in the expression passed as the Assertion Method's arguments.
Delta Assertions
If we are using a Shared Fixture (page X), we may find that we have Interacting Tests (see Erratic Test on page X) because each test adds more objects/rows into the database and we can never be certain exactly what should be there after the SUT has been exercised. One way to deal with the uncertainty is to use Delta Assertions (page X) to verify only the newly added objects/rows. This involves taking some sort of snapshot of the relevant tables/classes at the beginning of the test and then removing them from the collection of actual objects/rows we end up with at the end of the test before comparing them to the Expected Objects. This can introduce significant extra complexity into the tests but this complexity can be refactored out into Custom Assertions and/or Verification Methods (see Custom Assertion). The "before" snapshot may be taken inline within the Test Method or in the setUp method if all setup is done before the Test Method is invoked (e.g. Implicit Setup, a Shared Fixture or a Prebuilt Fixture (page X).)
External Result Verification
Thus far I've assumed that we are using conventional "in-memory" verification of the expected results. There is another approach that involves storing the expected and actual results in files and using an external comparison program to report on any differences. This is, in effect, a form of Custom Assertion that uses a "deep compare" on two file references. The comparison program often needs to be told what parts of the files to ignore (or these parts are stripped out first) effectively making this a Fuzzy Equality Assertion.
External result verification is particularly appropriate for automating acceptance tests for regression testing an application that hasn't changed very much. The big downfall of this approach is that we almost always end up with a Mystery Guest (see Obscure Test) from the test reader's perspective because the expected results are not visible inside the test. One way to avoid this is to have the test write the contents of the expected file thus making it visible to the test reader. This is only practical if the amount of data is quite small - another argument in favor of a Minimal Fixture (page X).
Verifying Behavior
Verifying behavior is more complicated that verifying state because behavior is dynamic. We have to catch the SUT "in the act" as it generates indirect outputs to the objects it depends on. There are two basic styles of behavior verification, Procedural Behavior Verification (see Behavior Verification) and Expected Behavior (see Behavior Verification). Both require a mechanism to access the outgoing method calls of the SUT (its indirect outputs.) This and other uses of Test Doubles (page X) are described in more detail in Using Test Doubles.
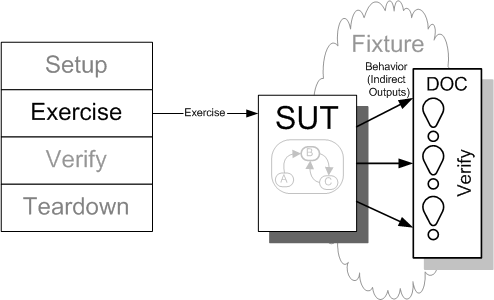
Sketch Behavior Verification embedded from Behavior Verification.gif
Fig. X: Behavior Verification.
In Behavior Verification we focus our assertions on the indirect outputs (outgoing interfaces) of the SUT. This typically involves replacing the DOC with something that facillitates observing and verifying the outgoing calls.
Procedural Behavior Verification
In Procedural Behavior Verification we capture the behavior of the SUT as it executes and save it for later retrieval. The test then compares each output of the SUT (one by one) with the corresponding expected output. I call this Procedural Behavior Verification because the test executes a procedure (a set of steps) to verify the behavior.
public void testRemoveFlightLogging_recordingTestStub() throws Exception {
// fixture setup
FlightDto expectedFlightDto = createAnUnregFlight();
FlightManagementFacade facade = new FlightManagementFacadeImpl();
// Test Double setup
AuditLogSpy logSpy = new AuditLogSpy();
facade.setAuditLog(logSpy);
// exercise
facade.removeFlight(expectedFlightDto.getFlightNumber());
// verify
assertEquals("number of calls", 1, logSpy.getNumberOfCalls());
assertEquals("action code", Helper.REMOVE_FLIGHT_ACTION_CODE,
logSpy.getActionCode());
assertEquals("date", helper.getTodaysDateWithoutTime(), logSpy.getDate());
assertEquals("user", Helper.TEST_USER_NAME, logSpy.getUser());
assertEquals("detail", expectedFlightDto.getFlightNumber(),
logSpy.getDetail());
}
Example ProceduralBehaviorVerification embedded from java/com/clrstream/ex8/test/FlightManagementFacadeTestSolution.java
The key challenge in Procedural Behavior Verification is capturing the behavior as it occurs and saving it until the test is ready to use it. This is done by configuring the SUT to use a Test Spy (page X) or a Self Shunt (see Hard-Coded Test Double on page X)(A Test Spy built right into the Testcase Class (page X)) instead of the depended-on class. After the SUT has been exercised, the test retrieves the recording of the behavior and verifies it using assertions.
Expected Behavior Specification
If we can build an Expected Object and compare it with the actual object returned by the SUT for verifying state, can we do something similar for verifying behavior? Yes, we can and do. Expected Behavior is a common technique when using layer-crossing tests to verify the indirect outputs of an object or component. We configure a Mock Object (page X) with the method calls we expect the SUT to make to it and install it before exercising the SUT.
public void testRemoveFlight_JMock() throws Exception {
// fixture setup
FlightDto expectedFlightDto = createAnonRegFlight();
FlightManagementFacade facade = new FlightManagementFacadeImpl();
// mock configuration
Mock mockLog = mock(AuditLog.class);
mockLog.expects(once()).method("logMessage")
.with(eq(helper.getTodaysDateWithoutTime()), eq(Helper.TEST_USER_NAME),
eq(Helper.REMOVE_FLIGHT_ACTION_CODE),
eq(expectedFlightDto.getFlightNumber()));
// mock installation
facade.setAuditLog((AuditLog) mockLog.proxy());
// exercise
facade.removeFlight(expectedFlightDto.getFlightNumber());
// verify
// verify() method called automatically by JMock
}
Example ExpectedBehavior embedded from java/com/clrstream/ex8/test/FlightManagementFacadeTestSolution.java
Reducing Test Code Duplication
One of the most common test smells is Test Code Duplication. With every test we write, there is a good chance we have introduced some duplication especially if we used "cut and paste" to create a new test from an existing test. Some will argue that duplication in test code is not nearly as bad as duplication in production code. I feel that Test Code Duplication is bad if it leads to some other smell such as Fragile Test (page X), Fragile Fixture (see Fragile Test) or High Test Maintenance Cost (page X) because too many tests are too closely coupled to the Standard Fixture (page X) or the API of the SUT. The other thing to watch for is when Test Code Duplication is a symptom of another problem: the intent of the tests being obscured by too much code: an Obscure Test.
In result verification logic, Test Code Duplication usually shows up as a set of repeated assertions. There are a several techniques to reduce the number of assertions including:
Expected Objects
Often, we will find ourself doing a series of assertions on various fields of the same object. This may seem OK the first time but if we find ourselves repeating this group of assertions over and over (whether multiple times in a single test or in multiple tests) we should look for a way to reduce the Test Code Duplication.
public void testInvoice_addLineItem7() {
LineItem expItem = new LineItem(inv, product, QUANTITY);
// Exercise
inv.addItemQuantity(product, QUANTITY);
// Verify
List lineItems = inv.getLineItems();
LineItem actual = (LineItem)lineItems.get(0);
assertEquals(expItem.getInv(), actual.getInv());
assertEquals(expItem.getProd(), actual.getProd());
assertEquals(expItem.getQuantity(), actual.getQuantity());
}
Example NaiveInlineAssertions embedded from java/com/clrstream/camug/example/test/InvoiceTest.java
The most obvious alternative is to use a single Equality Assertion to compare two whole objects to each other rather than using many Equality Assertion calls to compare them field by field. If we have the values in stored in individual variables we may need to create a new object of the appropriate class and initialize its fields with the values we have stored in individual variables. This technique works as long as we have an equals method that compares only those fields and we have the ability to create the Expected Object at will.
public void testInvoice_addLineItem8() {
LineItem expItem = new LineItem(inv, product, QUANTITY);
// Exercise
inv.addItemQuantity(product, QUANTITY);
// Verify
List lineItems = inv.getLineItems();
LineItem actual = (LineItem)lineItems.get(0);
assertEquals("Item", expItem, actual);
}
Example NaiveExpectedObjectUsage embedded from java/com/clrstream/camug/example/test/InvoiceTest.java
What can we do if we don't want to compare all the fields in an object or if the equals method looks for identity rather than equality? What if we want test-specific equality? What if we cannot create an instance of the Expected Object because no constructor exists? We have two options: We can implement our own Custom Assertion (discussed below) that defines equality the way we want it or we can implement our test-specific equality in the equals method of the class of the Expected Object we pass to the Assertion Method. This class doesn't need to be the same class as the actual object; it just needs to implement equals to compare itself with one. Therefore, it can be a simple Data Transfer Object[CJ2EEP] or it could be a Test-Specific Subclass (page X) of the real (production) class with just the equals method overridden.
public void testInvoice_addLineItem1() {
LineItem expItem = new LineItem(inv, product, QUANTITY);
// Exercise
inv.addItemQuantity(expItem.getProd(), expItem.getQuantity());
// Verify
List lineItems = inv.getLineItems();
assertEquals("number of items", lineItems.size(), 1);
LineItem actual = (LineItem) lineItems.get(0);
assertEquals("Item", expItem, actual);
}
Example ExpectedObjectUsage embedded from java/com/clrstream/camug/example/test/InvoiceTest.java
Some test automaters don't think we should ever rely on the equals method of the SUT when doing assertions because it could change thus causing tests that depend on it to fail (or to miss important differences.) I prefer to be pragmatic about this decision. If it seems reasonable to use the equals definition supplied by the SUT then I will use it. If I need something else, I define a Custom Assertion or a test-specific Expected Object class. I also ask myself how hard it would be to change strategy should the equals method change. For example, in statically-typed languages that support parameter type overloading (such as Java) we can add a Custom Assertion that uses different parameter types to override the default implementation when specific types are used. This can often be retrofitted quite easily if a change to equals causes problems.
Custom Assertions
A Custom Assertion is a domain-specific assertion we write ourselves. Custom Assertions hide the procedure for verifying the results behind a declarative name thereby making our result verification logic more intent revealing. They also prevent Obscure Test by eliminating of a lot of potentially distracting code. Another benefit of moving the code into a Custom Assertion is that the assertion logic can now be unit tested by writing Custom Assertion Tests (see Custom Assertion). The assertions are no longer Untestable Test Code (see Hard to Test Code on page X)!
static void assertLineItemsEqual( String msg, LineItem exp, LineItem act) {
assertEquals(msg+" Inv", exp.getInv(),act.getInv());
assertEquals(msg+" Prod", exp.getProd(), act.getProd());
assertEquals(msg+" Quan", exp.getQuantity(), act.getQuantity());
}
Example CustomAssertionMethodCamug embedded from java/com/clrstream/camug/example/test/InvoiceTest.java
There are two common ways to create Custom Assertions: The first is through refactoring existing complex test code to reduce Test Code Duplication. The second is to code calls to non-existent Assertion Methods as we write tests and then filling in the method bodies with the appropriate logic once we have landed on the suite of Custom Assertions needed by a set of Test Methods. This is a good way of reminding ourselves what we expect the outcome of exercising the SUT to be even though we haven't yet written the code to verify it. Either way, the definition of a set of Custom Assertions is the first step towards creating a Higher Level Language (see Principles of Test Automation on page X) for specifying our tests.
When refactoring to Custom Assertions we simply use Extract Method[Fowler] on the repeated assertions and give the new method an Intent Revealing Name[SBPP]. We pass in the objects used by the existing verification logic as arguments and include an Assertion Message to differentiate between calls to the same assertion method.
Outcome Describing Verification Method
Another technique that is born from ruthless refactoring of test code is the "outcome describing" Verification Method. Suppose we find that a group of tests all have identical exercise SUT and verify outcome sections. Only the setup portion is different. If we do an Extract Method refactoring on the common code and give it a meaningful name, we achieve less code, more understandable tests and testable verification logic all at the same time! If this isn't a worthwhile reason for refactoring code I don't know what else could be.
void assertInvoiceContainsOnlyThisLineItem( Invoice inv,
LineItem expItem) {
List lineItems = inv.getLineItems();
assertEquals("number of items", lineItems.size(), 1);
LineItem actual = (LineItem)lineItems.get(0);
assertLineItemsEqual("",expItem, actual);
}
Example VerificationMethod embedded from java/com/clrstream/camug/example/test/InvoiceTest.java
The main difference between a Verification Method and a Custom Assertion is that the latter only does asserting while the former also interacts with the SUT typically for the purpose of exercising it. Another common difference is that Custom Assertions typically have a standard Equality Assertion signature ( assertSomething(message, expected, actual)) while Verification Methods may have completely arbitrary parameters because they require additional parameters to pass into the SUT. They are, in essence, halfway between a Parameterized Test (page X) and a Custom Assertion.
Parameterized and Data-Driven Tests
We can go even farther in factoring out the commonality between tests. If the logic to set up the test fixture is the same but uses different data, we can extract the common fixture setup , exercise SUT and verify outcome phases of the test into a new Parameterized Test method. The Parameterized Test is not called automatically by the Test Automation Framework (page X) because it requires arguments; instead, we define very simple Test Methods for each test but all they do is call the Parameterized Test passing in the data required to make this test unique. This may include data required for fixture setup, exercising the SUT, and the corresponding expected result. In the following tests, the method generateAndVerifyHtml is the Parameterized Test.
def test_extref
sourceXml = "<extref id='abc' />"
expectedHtml = "<a href='abc.html'>abc</a>"
generateAndVerifyHtml(sourceXml,expectedHtml,"<extref>")
end
def test_testterm_normal
sourceXml = "<testterm id='abc'/>"
expectedHtml = "<a href='abc.html'>abc</a>"
generateAndVerifyHtml(sourceXml,expectedHtml,"<testterm>")
end
def test_testterm_plural
sourceXml = "<testterms id='abc'/>"
expectedHtml = "<a href='abc.html'>abcs</a>"
generateAndVerifyHtml(sourceXml,expectedHtml,"<plural>")
end
Example ParamterizedTestUsage embedded from Ruby/CrossrefHandlerTest.rb
In a Data-Driven Test (page X), the test case is completely generic and directly executable by the framework; it reads the arguments from a test data file as it executes. We can think of a Data-Driven Test as a Parameterized Test turned inside out: a Test Method passes test-specific data to a Parameterized Test, in contrast, a Data-Driven Test is the Test Method and reads the test-specific data from a file. The contents of the file are a Higher Level Language for testing and the Data-Driven Test is the Interpreter[GOF]. This is the xUnit equivalent of a FIT test.
def test_crossref
executeDataDrivenTest "CrossrefHandlerTest.txt"
end
def executeDataDrivenTest filename
dataFile = File.open(filename)
dataFile.each_line do | line | desc, action, part2 = line.split(",")
sourceXml, expectedHtml, leftOver = part2.split(",") if "crossref"==action.strip generateAndVerifyHtml sourceXml, expectedHtml, desc
else # new "verbs" go before here as elsif's
report_error( "unknown action" + action.strip )
end
end
end
Example DataDrivenTestInterpreter embedded from Ruby/DataDrivenTestInterpreter.rb
Here is the data file the test reads:
ID, Action, SourceXml, ExpectedHtml Extref,crossref,<extref id='abc'/>,<a href='abc.html'>abc</a> TTerm,crossref,<testterm id='abc'/>,<a href='abc.html'>abc</a> TTerms,crossref,<testterms id='abc'/>,<a href='abc.html'>abcs</a> Example DataDrivenTestTxt embedded from Ruby/CrossrefHandlerTest.txt
Avoiding Conditional Test Logic
Another thing we want to avoid in our tests is conditional logic. Conditional Test Logic (page X) is bad because the same test may execute differently in various circumstances. Conditional Test Logic reduces our trust in the tests because the code in our Test Methods is Untestable Test Code. Why is this important? Because the only way we can verify our Test Method is to manually edit the SUT to cause the error we want to see detected. If the Test Method has many paths through it, we need to make sure each path is coded correctly. Isn't it so much simpler just to have only one possible execution path through the test? Let us look at some reasons why we might have conditional logic in our tests:
- We don't want to execute certain assertions because it doesn't make sense given what we have already discovered at this point in the test (typically a failure condition)
- We have to allow for various situations in the actual results that we are comparing to the expected results
- We are trying to reuse a Test Method in several different circumstances (essentially several tests merged into a single Test Method.)
I feel the last reason is just a bad idea, plain and simple. There are much better ways of reusing test logic than to try to reuse the Test Method itself. We have already seen some of these reuse techniques elsewhere in this chapter (in Reducing Test Code Duplication) and we will see other ways elsewhere in this book. Just say "no"!
The problem with using Conditional Test Logic in the first two cases is that it makes the code hard to read and may mask cases of reusing test methods via Flexible Tests (see Conditional Test Logic). The good news is that it is relatively straightforward to remove all legitimate uses of Conditional Test Logic from our tests.
Eliminating If Statements
What should we do when we don't want to execute an assertion because we know it will result in a test error and we'd prefer to have more meaningful test failure message? The normal initial reaction is to put an "if" statement around the assertion. Unfortunately this results in the Conditional Test Logic which we would dearly like to avoid because we want exactly the same code to run each time we run the test.
List lineItems = invoice.getLineItems();
if (lineItems.size() == 1) {
LineItem expected = new LineItem(invoice, product,5, new BigDecimal("30"),
new BigDecimal("69.96"));
LineItem actItem = (LineItem) lineItems.get(0);
assertEquals("invoice", expected, actItem);
} else {
fail("Invoice should have exactly one line item");
}
Example CamugIfStatements embedded from java/com/clrstream/camug/example/test/TestRefactoringExample.java
The preferred solution is to use a Guard Assertion (page X) instead. The nice thing about Guard Assertions is that they keep us from hitting the assertion that would cause a test error but without introducing Conditional Test Logic. Once we get used to them they are pretty obvious and intuitive to read. We may even find ourselves wanting to assert the pre-conditions of our methods in our production code!
List lineItems = invoice.getLineItems();
assertEquals("number of items", lineItems.size(), 1);
LineItem expected = new LineItem(invoice, product, 5, new BigDecimal("30"),
new BigDecimal("69.96"));
LineItem actItem = (LineItem) lineItems.get(0);
assertEquals("invoice", expected, actItem);
Example CamugGuardAssertion embedded from java/com/clrstream/camug/example/test/TestRefactoringExample.java
Eliminating Loops
Another common reason for Conditional Test Logic is the use of loops to verify that the contents of a collection returned by the SUT matches what we expected. Putting loops directly into the Test Method creates two problems:
- It introduces Untestable Test Code because the looping code, being part of the test, cannot be tested with Fully Automated Tests (see Goals of Test Automation).
- It leads to Obscure Test because all that looping code obscures the real intent: does the collection match or doesn't it?
- It can also lead to the project-level smell Developers Not Writing Tests (page X) because the complexity of writing the loops may discourage the developer from writing the Self-Checking Test.
A better solution is to delegate this logic to a Test Utility Method.
Other Techniques
The following are some other useful techniques for writing easy to understand tests.
Working Backwards, Outside-In
A useful little trick for writing very intent-revealing code is to work backwards. This is an application of Stephen Covey's idea of "Start with the end in mind". To do this we write the last line of the function or test first. With a function, it's whole reason for existence is to return a value; with a procedure it is to have one or more side-effects by modifying something. With a test, the raison d'etre is to verify that the expected outcome has occurred (by making assertions.)
Working backwards means we write these assertions first. We assert on the values of suitably named local variables to ensure the assertion is intent-revealing. The rest of writing the test is simply filling in whatever is needed to execute those assertions: We declare and initialize the assertion arguments with the appropriate content. Since at least one should have been retrieved from the SUT we must of course, invoke the SUT. To do that we may need some variables to use as SUT arguments, etc. Declaring and initializing a variable after it has been used forces us to understand it better when we first introduce it. It results in better variable names and avoids meaningless names like invoice1 and invoice2.
Working "outside-in" (or "top-down" as it is sometimes called) means staying at a consistent level of abstraction. The Test Method should focus on what we need to have in place to induce the relevant behavior in the SUT. The mechanics of how we get that into place should be delegated to a "lower layer" of test software. We achieve this in practice by coding them as calls to Test Utility Methods; this allows us to stay focused on the requirements of the SUT as we write the Test Method. We don't need to worry about how we will create that object or verify that outcome; we only need to describe what that object or outcome should be! The utility method we just used but haven't yet defined acts as a placeholder for the unfinished test automation logic. (We should always give it an Intent Revealing Name and stub it out with a call to the fail assertion to remind ourselves that we still need to write the body.) We can move on to writing the other tests we need for this SUT while they are still fresh in our minds. Later, we can switch to wearing our "toolsmith" hat to implement the Test Utility Method.
Using TDD to Write Test Utilility Methods
Once we are finished writing the Test Method(s) that used the Test Utility Method, we can start the process of writing the Test Utility Method itself. We can do this using test-driven development by writing Test Utility Tests (see Test Utility Method). It doesn't take very long to write these unit tests that verify the behavior of the our Test Utility Methods and we will have much more confidence in them.
We start with the simple case (say, assertion the equality of two identical collections with a same item in them) and work up to the most complicated case that the tests actually require (say, two collections with the same 2 items but in different order.) TDD helps us find the minimal implementation of the method and it may be much simpler than a complete generic solution. There is no point in writing generic logic that handles cases that aren't actually needed but it may be worthwhile including a Guard Assertion or two inside the Custom Assertion to document which cases it doesn't support.
Where to Put Reusable Verification Logic?
So we've decided to use Extract Method refactoring to create some reusable Custom Assertions or we have decided to write our tests in an intent-revealing way using Verification Methods. Where should we put these bits of reusable test logic? The most obvious place is in the Testcase Class (page X) itself. We can allow them to be reused more broadly by using a Pull Up Method[Fowler] refactoring to move them up to a Testcase Superclass (page X) or a Move Method[Fowler] refactoring to move them to a Test Helper (page X). I discuss this in more detail in the chapter Organizing Our Tests.
What's Next?
This discussion of techniques for verifying the expected outcome concludes our introduction to the basic techniques of automating tests using xUnit. In the Using Test Doubles narrative I introduce some advanced techniques involving the use of Test Doubles.Copyright © 2003-2008 Gerard Meszaros all rights reserved