
Test Automation Strategy
The book has now been published and the content of this chapter has likely changed substanstially.About This Chapter
In previous chapters we have seen some of the problems we can encounter with test automation; in the Principles of Test Automation narrative we some of the principles we can apply to help address them. In this chapter I get a bit more concrete but still focus at the 30,000 foot level. In the logical sequence of things, test strategy comes before fixture set up but it is a somewhat more advanced topic. If you are new to test automation using xUnit you may want to skip this chapter and come back after reading more about the basics of xUnit in the XUnit Basics narrative and fixture set up and tear down in the Transient Fixture Management narrative and the subsequent chapters.
What's Strategic?
As I described in the story in the preface, it is easy to get off on the wrong foot. This is especially true when one lacks experience in test automation and when it is adopted "bottom up". If we catch the problems early enough, the cost of refactoring the tests to eliminate the problems can be manageable. If, however, the problems are left to fester for too long or the wrong approach is taken to address them, a very large amount of effort can be wasted. This is not to suggest that we should follow a "big design, up front" (BDUF) approach to test automation. BDUF is almost always the wrong answer. What I'm suggesting is that it is helpful to be aware of the strategic decisions we need to make and to make them "just in time" rather than "much too late". This chapter is intended to give us a "head's up" about some of the strategic issues we want to keep in mind so that we don't get blind-sided by them later.
So what makes a decision strategic? A decision is strategic if it is "hard to change". That is, a strategic decision is any decision that affects a large number of tests and especially where many or all the tests would need to be converted to a different approach at the same time. Or put another way, any decision that could cost a large amount of effort to change.
Common strategic decisions include:
- Which kinds of tests to automate?
- What tools to use to automate them?
- How to manage the test fixture?
- How to ensure that the system is easily tested and how the tests interact with the system under test (SUT)?
Each of these decisions can have far-reaching consequences so they are best made consciously, at the right time and based on the best available information.
It is worth noting that the strategies and more detailed patterns described in this book are equally applicable regardless of the kind of Test Automation Framework (page X) we choose to use. Most of my experience is with xUnit so it is the focus of this book but "Don't throw out the baby with the bath water." if you find yourself using a different kind of Test Automation Framework as most of what you learn in xUnit can be applied everywhere.
What Kinds of Tests Should We Automate?
Roughly speaking, we can divide tests into the following two categories:
- Per-functionality tests (A.K.A. functional tests) verify the behavior of the SUT in response to a particular stimulus.
- Cross-functional tests verify various aspects of the system's behavior that cut across specific functionality.
The following diagram shows these two basic kinds of tests as the two columns each of which is further subdivided into more specific kinds of tests.
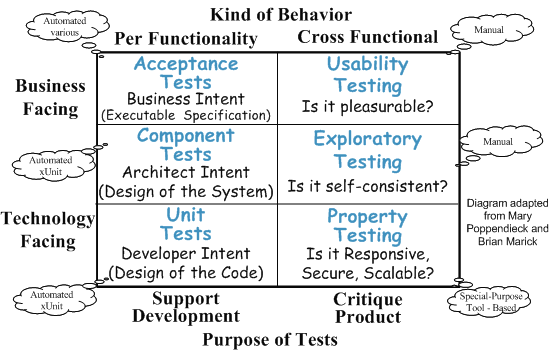
Sketch Kinds of Tests embedded from Kinds of Tests.gif
Fig. X: A summary of the kinds of tests we write and why.
The left column contains the tests we write that describe the functionality of the product at various levels of granularity; we do this to support development. The right column contains tests that span specific chunks of functionality; we execute these tests to critique the product. The bottom of each cell describes what we are trying to communicate or verify.
Per-Functionality Tests
Per-functionality tests verify the directly observable behavior of a piece of software in response to specific stimuli. The functionality can be business related (e.g. the principle use cases of the system) or related to operational requirements including system maintenance and specific fault tolerance scenarios. Most of these requirements can also be expressed as use cases, features, user stories or test scenarios. These tests can be characterized by whether or not the functionality is business (or user) facing and by the size of the SUT on which they operate:
Customer Tests
Customer tests verify the behavior of the entire system or application. These typically correspond to scenarios of one or more use cases, features or user stories. These tests often go by other names such as functional test, acceptance test or "end user test". They may be automated by developers but the key characteristic is that an end user should be able to recognize the behavior specified by the test even if they cannot read the test representation.
Unit Tests
Unit tests verify the behavior of a single class or method. These tests verify behavior that is a consequence of a design decision. This behavior is typically not directly related to the requirements except when a key chunk of business logic is encapsulated within the class or method in question. These tests are written by developers for their own use; they help them describe what "done looks like" by summarizing the behavior of the unit in the form of tests.
Component Tests
Component tests verify components consisting of groups of classes that collectively provide some service. These fit somewhere between the unit tests and customer tests in the size of the SUT being verified. I've heard people call these "integration tests" or "subsystem tests" but these terms can mean something entirely different than "tests of a specific larger-grained subcomponent of the overall system".
Note that fault insertion tests typically show up at all three levels of granularity within these per-functionality tests with different kinds of faults being inserted at each level. From a test automation strategy point of view, fault-insertion is just another set of tests at the unit and component test levels but it gets more interesting at the whole application level. This is due to the fact that inserting faults here can be hard to automate because it is hard to automate insertion of the faults without replacing parts of the application.
Cross-Functional Tests
Property Tests
Performance tests verify various "non-functional" (also known as "extra-functional" or "cross functional") requirements of the system. These requirements are different in that they span the various kinds of functionality. They often correspond to the architectural "-ilities". These kinds of tests include:
- Response time tests
- Capacity tests
- Stress tests
From a test automation perspective, many of these tests must be automated (at least partially) because human testers would have a hard time creating enough load to verify the behavior under stress. While we can run the same test many time in a row in xUnit, the xUnit framework is not particularly well-suited to automating performance tests.
One advantage of agile methods is that we can start running these kinds of tests quite early in the project: as soon as the key components of the architecture have been roughed in and the skeleton of the functionality is executable. The same tests can be run continuously throughout the project as new features are added to the system skeleton.
Usability Tests
Usability tests verify "fitness for purpose" by verifying that real users can use the software application to achieve stated goals. These tests are very difficult to automate because they require subjective assessment by people as to how easy it is to use the SUT. For this reason, usability tests are rarely automated and will not be discussed further in this book.
Exploratory Testing
Exploratory testing is a way to determine whether the product is self-consistent. The testers use the product, observe how it behaves, form hypotheses, design tests to verify those hypotheses and exercise the product with them. By its very nature, exploratory testing cannot be automated although automated tests can be used to set up the SUT in preparation for doing exploratory testing.
What Tools Do We Use to Automate Which Tests?
Using the right tool for the job is as important as having good skills with the tools we use. There is a wide array of tools available in the marketplace and it is easy to be seduced by the features of a particular tool. The choice of tool is a strategic decision because once we have invested a lot of time and effort learning a tool and automating many tests using that tool it becomes much harder to change to a different tool.
There are two fundamentally different approaches to automating tests. The Recorded Test (page X) approach involves the use of tools that monitor our interactions with the SUT while we test it manually. This information is then saved to a file or database and becomes the script for replaying this test against another (or even the same) version of the SUT. The main problem with Recorded Tests is the level of granularity they record. Most commercial tools record actions at the user-interface element level which results in Fragile Tests (page X).
The Hand-Scripted Test (see Scripted Test on page X) approach involves the hand-coding of test programs (a.k.a. "scripts") that exercise the system. While xUnit is probably the most commonly used Test Automation Framework for preparing Hand-Scripted Tests, there are other ways of preparing them including "batch" files, macro languages and commercial or open source test tools. Some of the better known open source tools for preparing Scripted Tests are Watir (test scripts coded in Ruby and run inside Internet Explorer), Canoo WebTest (tests scripted in XML and run using the WebTest tool)and the ever popular Fit (and it's wiki-based sibling Fitnesse. Some of these tools even provide a test capture capability thus blurring the lines between Scripted Tests and Recorded Tests.
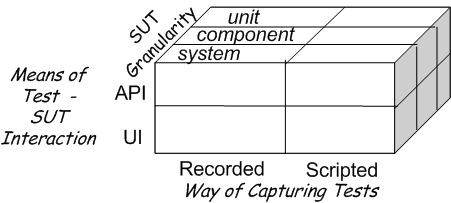
Sketch Test Automation Choices embedded from Test Automation Choices.gif
Fig. X: A summary of the three dimensions of test automation choices.
The left side gives us the two ways of interacting with the SUT; the bottom edge enumerates how we create the test scripts; the front-to-back dimension categorizes the different sizes of SUT we may choose to test.
Choosing what tools to use is a large part of the test strategy question but a full survey of the different kinds of tools is beyond the scope of this book. A somewhat more detailed treatment of the topic is available in [ARTRP]. I summarize the information here to provide an overview of the strengths and weaknesses of each approach.
Test Automation Ways and Means
In theory, there are 2x2x3 possible combinations in this matrix but it is possible to understand the primary differences between the approaches by looking at the front face of the cube. Some of the four quadrants are applicable to all levels of granularity while others are primarily used for automating customer tests.

Sketch Test Automation Ways and Means embedded from Test Automation Ways and Means.gif
Fig. X: The choices on the front face of the cube.
A more detailed look at the front face of the cube in the previous figure along with the advantages (+) and disadvantages of each (-).
Upper Right Quadrant - Modern xUnit
The upper right quadrant of the front face of the cube is dominated by the xUnit family of testing frameworks. It involves hand-scripting tests that exercise the system at all 3 levels of granularity (system, component or unit) via internal interfaces. A good example of this is unit tests automated using JUnit or NUnit.
Bottom Right Quadrant - Scripted UI Tests
This is a variation on the "modern xUnit" approach with the most common examples being the use of HttpUnit, JFCUnit, Watir or similar tools to hand-script tests using the user interface. It is also possible to hand-script tests using commercial Recorded Test tools such as QTP. These approaches all sit into the bottom right quadrant at various levels of SUT granularity. For example, when used for customer tests, it would be at the system test level of granularity. They could also be used to test just the user interface component of the system (or possibly even some UI units such as custom widgets) but this would require stubbing out the actual system behind the UI.
Bottom Left Quadrant - Robot User
This is the "Robot User" quadrant. It involves recording tests that interact with the system via the user interface; it is the approach employed by most commercial test automation tools. It applies primarily at the "whole system" granularity but like “scripted UI Tests”, it could be applied to the UI components or units if the rest of the system can be stubbed out.
Top Left Quadrant - Internal Recording
For completeness, the top left quadrant involves creating Recorded Tests via an API somewhere behind the user interface by recording all inputs and responses as the SUT is exercised. It may even involve inserting observations points between the SUT (at whatever granularity we are testing) and any depended-on component (DOC). During test playback, the test APIs are used to inject the inputs recorded earlier and to compare the results with what was recorded
This quadrant is not well populated with commercial tools(Most of the tools in this quadrant focus on recording regression tests by inserting observation points into a component-based application and recording the (remote) method calls and responses between the components.) but is a feasible option when building a Recorded Test mechanism into the application itself.
Introducing xUnit
The xUnit family of Test Automation Frameworks is designed for use in automating programmer tests. The design parameters are:
- Make it easy for developers to write tests without needing to learn a new programming language. xUnit is available in most languages in use today.
- Make it easy to test individual classes and objects without needing to have the rest of the application available. xUnit is designed to allow us to test the software from the inside; we just have to design for testability to be able to take advantage of this.
- Make it easy to run one test or many with a single simple action. xUnit includes the concept of a test suite and Suite of Suites (see Test Suite Object on page X) to enable this.
- Minimize the cost of running the tests so programmers aren't discouraged from running the tests they have. This is why each test should be a Self-Checking Test (see Goals of Test Automation on page X) that implements the Hollywood Principle(Named after what directors in Hollywood tell aspiring applicants at mass casting calls: "Don't call us; we'll call you (if we want you.)").
The xUnit family has been extraordinarily successful at meeting it's goals. I cannot imagine that Erich Gamma and Kent Beck could have possibly anticipated just how big an impact that first version of JUnit would have on software development! (Technically, SUnit came first but it took JUnit and the "Test Infected" article [TI] to really get things rolling.) The same things that make xUnit particularly suited to automating programmer tests may make it less suitable for writing some other kinds of tests. In particular, the "stop on first failure" behavior of assertions in xUnit has often been criticized (or overridden) by people wanting to use xUnit for automating multi-step customer tests so that they can see the whole score (what worked and what didn't) rather than merely the first deviation from the expected results. This points out several things:
- "Stop on first failure" is a tool philosophy, not a characteristic of unit tests although most people prefer to have their unit tests stop on first failure and most recognize that customer test must necessarily be longer than unit tests.
- It is possible to change the fundamental behavior of xUnit to satisfy specific needs; this is just one advantage of open source tools.
- Seeing a need to change the fundamental behavior of xUnit should probably be interpreted as a trigger for considering whether some other tool might possibly be a better fit.
For example, the Fit framework has been designed specifically for the purpose of running customer tests. It overcomes the limitations of xUnit that lead to the "stop on first failure" behavior by communicating the pass/fail status of each step of a test using color coding.
Having said this, choosing to use a different tool doesn't eliminate the need to make many of the strategic decisions unless the tool constrains us is some way. For example, we still need to set up the test fixture for a FIT test. Some patterns, like using Chained Tests (page X) --where one test sets up the fixture for a subsequent test-- are difficult to automate and may therefore be less attractive in FIT than in xUnit. Isn't it ironic that the very flexibility of xUnit is what allows test automaters to get themselves into so much trouble by creating Obscure Tests (page X) that result in High Test Maintenance Cost (page X)?
The xUnit Sweet Spot
The xUnit family works best when we can organize our tests as a large set of small tests that each require a small test fixture that is relatively easy to set up. This allows us to create a separate test for each test scenario of each object. The test fixture should be managed using a Fresh Fixture (page X) strategy by setting up a new Minimal Fixture (page X) for each test.
xUnit works best when we write tests against software APIs and we test single classes or small groups of classes in isolation. This allows us to build small test fixtures that can be instantiated quickly.
When doing customer tests (customer tests), xUnit works best if we define a Higher Level Language (see Principles of Test Automation) in which to describe our tests. This moves the level of abstraction higher, away from the nitty, gritty of the technology and closer to the business concepts that our customers understand. From here, it is a very small step to convert these tests to Data-Driven Tests (page X) of which Fit tests are a good example.
While on the topic of Fit, it is worth noting that many of the higher level patterns and principles I describe here apply equally to Fit tests. I have also found them to be useful when using commercial GUI-based testing tools that typically use a "record and playback" metaphor. The fixture management patterns are particularly salient in this arena as are the use of reusable "test components" that are strung together in different to form various test scripts. This is entirely analogous to the xUnit practice of single-purpose Test Methods (page X) calling reusable Test Utility Methods (page X) to reduce their coupling to the API of the SUT.
Which Test Fixture Strategy Do We Use?
The test fixture management strategy is strategic because it has a large impact on the execution time and robustness of the tests. The impact of picking the wrong strategy won't be felt immediately because it takes at least a few hundred tests before the Slow Tests (page X) start to make their impact felt and probably several months of development before the High Test Maintenance Cost start to be felt. Once they are felt, however, the need to change will become apparent and the cost of changing will be significant because of the number of tests affected.
What is a Fixture?
Every test consists of four parts as described in Four-Phase Test (page X). The first part is where we create the SUT and everything it depends on and put them into the state required to exercise the SUT. In xUnit, we call everything we need in place to exercise the SUT the test fixture and we call the part of the test logic that we execute to set it up the "fixture setup" phase of the test.
At this point, a word of caution is in order. The term "fixture" means many things to many people.
- Some variants ofxUnit keep the concept of the fixture separate from the Testcase Class (page X) that creates it; JUnit and its direct ports fall into this category.
- Other members of the xUnit family assume that an instance of the Testcase Class "is a" fixture; NUnit is a good example of this camp.
- A third camp uses an entirely different name for the fixture; RSpec captures the preconditions of the test in a test context class that hold the Test Methods (same idea as NUnit but with different terminology.)
- It is also worth noting here that the term fixture is used to mean entirely different things in other kinds of test automation. In Fit, the term fixture is used to mean the custom-built parts of the Data-Driven Test Interpreter[GOF] that we use to define our Higher Level Language.
The "class 'is a' fixture" approach assumes the Testcase Class per Fixture (page X) approach to organizing the tests. When we choose to use a different way of organizing the tests, such as Testcase Class per Class (page X) or Testcase Class per Feature (page X), this merging of the concepts of test fixture and Testcase Class can be confusing. Throughout this book, I use "test fixture" to mean "the preconditions of the test" and Testcase Class to mean "the class that contains the Test Methods and any code to set up the test fixture."
The most common way to set up the fixture is using front door fixture set up by calling the appropriate methods on the SUT to construct the objects. When the state of the SUT is stored in other objects or components, we can do Back Door Setup (see Back Door Manipulation on page X) by inserting the necessary records directly into the other component on which the behavior of the SUT depends. We use Back Door Setup most often with databases or when we need to use a Mock Object (page X) or Test Double (page X); I will cover these in more detail in the chapters on Testing With Databases and Using Test Doubles.)
The Three Major Fixture Strategies
There are probably many ways of classifying anything. For the purpose of this discussion, it is useful to classify our test fixture strategy from the perspective of what kinds of test development work we need to do for each one.
The simplest fixture management strategy only requires us to worry about how we organize the code to build the fixture for each test. That is, do we put this code in our Test Methods, factor it out into Test Utility Methods that we call from our Test Methods, or put it into a setUp method on our Testcase Class. This strategy involves the use of Transient Fresh Fixtures (see Fresh Fixture). These fixtures live only in memory and very conveniently disappear as soon as we are done with them.
The next strategy involves the use of Fresh Fixtures that for one reason or another persist beyond the single Test Method that uses it. To keep this from turning into a Shared Fixture (page X) strategy, these Persistent Fresh Fixtures (see Fresh Fixture) require explicit code to tear them down at the end of each test. This brings into play the fixture tear down patterns.
The final strategy involves persistent fixtures that are deliberately reused across many tests. This Shared Fixture strategy is often used to improve the execution speed of tests that use a Persistent Fresh Fixture but it comes with a fair amount of baggage. These test require the use of one of the fixture construction and tear down triggering patterns. They also involve tests that interact with each other, whether by design or consequence, and this often leads to Erratic Tests (page X) and High Test Maintenance Costs.
The fixture management overhead of the three styles of fixture are summarized in this table:
| SetUp Code | Tear Down Code | SetUp/TearDown Triggering | |
| Transient Fresh Fixture | Yes | ||
| Persistent Fresh Fixture | Yes | Yes | |
| Shared Fixture | Yes | Yes | Yes |
Table X: A summary of the fixture set up and tear down requirements of the various test fixture strategies. The Shared Fixture row assumes we are building a new Shared Fixture each test run.
The following diagram illustrates the interaction between our goals, freshness of fixtures or fixture reuse, and whether the fixture is persistent. It also illustrates a few variations of the Shared Fixture.
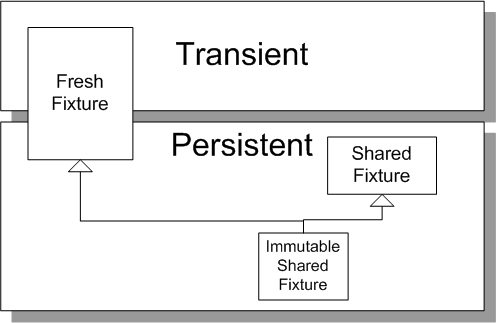
Sketch Test Fixture Strategies embedded from Test Fixture Strategies.gif
Fig. X: A summary of the main test fixture strategies.
Fresh Fixtures can be either transient or persistent; Shared Fixtures must be persistent. An Immutable Shared Fixture (see Shared Fixture) must not be modified by any test therefore most tests invariably augment the Shared Fixture with a Fresh Fixture they can modify.
The relationship between persistence and freshness is reasonably obvious for two of these combination. A persistent Fresh Fixture is discussed in more detail below. A transient Shared Fixture is inherently transient and it is how we hold references to them that makes them persist. Other than this one distinction, they can be treated exactly like persistent Shared Fixtures.
Transient Fresh Fixtures
In this approach, each test creates a temporary Fresh Fixture as it runs. Any objects or records it requires are created by the test itself. Because the test fixture visibility is restricted to the one test alone, we ensure that each test is completely independent because it cannot depend, either accidently or on purpose, on the output of any other tests that use the same fixture.
We call this approach Fresh Fixture because each test starts with a clean slate and builds from there. It does not "inherit" or "reuse" any part of the fixture from other tests or from a Prebuilt Fixture (page X). Every object or record used by the SUT is "fresh", "brand new" and not "previously enjoyed".
The main disadvantage of Fresh Fixture is the additional CPU cycles it takes to create all the objects for each test. This can make the tests run slower than a Shared Fixture approach, especially if it is a Persistent Fresh Fixture.
Persistent Fresh Fixtures
A Persistent Fresh Fixture sounds a bit oxymoronic. We want the fixture to be fresh yet we persist it! What kind of strategy is that? Some might say stupid but sometimes one has to do this.
We are "forced" into this when we are testing components that are tightly coupled to a database or other persistence mechanism. The obvious answer is that we should not let the coupling be so tight, that we should make the database a substitutable dependency of the component we are testing. This may not be practical when testing legacy software yet we may still want to partake of the benefits of a Fresh Fixture.
We can at least partially address the resulting Slow Tests by applying one or more of the following patterns:
- Construct a Minimal Fixture (the smallest possible fixture we possibly can).
- Speed up the construction by using a Test Double to replace the provider of any data that takes too long to set up.
- If the tests still are not fast enough, minimize the size of the part of the fixture we need to destroy and reconstruct each time by using an Immutable Shared Fixture for any objects that are referenced but not modified.
The project teams that I have worked with have found that, on average, our tests run fifty times faster (yes, take 2% as long) when we use Dependency Injection (page X) or Dependency Lookup (page X) to replace the entire database with a Fake Database (see Fake Object on page X) that uses a set of HashTables instead of tables. This is because a test may do many, many database operations to set up and tear down the fixture required by a single query in the SUT.
There is a lot to be said for minimizing the size and complexity of the test fixture. A Minimal Fixture (see Minimal Fixture) is much easier to understand and helps highlight the "cause and effect" relationship between the fixture and the expected outcome. In this regard, it is a major enabler of Tests as Documentation (see Goals of Test Automation). In some cases, we can make the test fixture much smaller by using Entity Chain Snipping (see Test Stub on page X) to eliminate the need to instantiate objects on which our test depends only indirectly. This will certainly speed up the instantiation of our test fixture.
Shared Fixture Strategies
There will be times when we cannot or choose not to use a Fresh Fixture strategy. In these cases, we can use a Shared Fixture. This approach involves having many tests reuse the same instance of a test fixture.
The main advantage of Shared Fixtures is that we save a lot of execution time setting up and tearing down the fixture. The main disadvantage is conveyed by one of its aliases, Stale Fixture, and by the test smell that describe its most common side effects, Interacting Tests (see Erratic Test). Shared Fixtures do have other benefits but most can be realized through other patterns applied to Fresh Fixtures; Standard Fixture (page X) avoids the fixture design and coding effort for every test without actually sharing the fixture.
Now, if Shared Fixtures are so bad, why am I even talking about them? Everyone seems to end up going down this road at least once in their career and we might as well share the best available information about them should we go down that path. Mind you, I don't want to encourage anyone to go down this path unnecessarily because the paths is paved with broken glass, infested with poisonous snakes and ... well, you get my drift.
Given that we have decided to use a Shared Fixture (we did investigate every possible alternative, didn't we?) what are our options? We can adjust:
- how far and wide we share a fixture (a Testcase Class, all tests in a test suite, all test run by a particular user, etc.)
- how often we recreate the fixture.
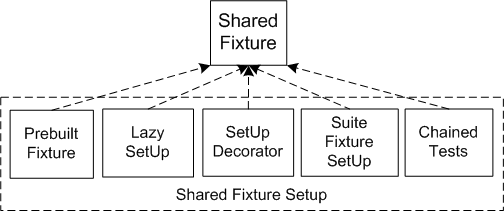
Sketch Shared Fixture Setup embedded from Shared Fixture Setup.gif
Fig. X: The various ways we can manage a Shared Fixture.
The strategies are ordered by the lenght of fixture lifetime with the longest lasting fixture on the left.
The more tests that share a fixture the more likely one of them is to make a mess of it and spoil everything for all the tests that follow. The less often we reconstruct the fixture, the longer the impact of a messed up fixture will persist. For example, a Prebuilt Fixture can be set up outside the test run thereby entirely avoiding the cost of setting up the fixture as part of the test run but it can result in Unrepeatable Tests (see Erratic Test) if tests don't clean up after themselves properly. It is most commonly used with a Database Sandbox (page X) that is initialized using a database script; once the fixture is corrupted, it must be reinitialized by rerunning the script. If the Shared Fixture is accessible by more than one Test Runner (page X) we can end up in a Test Run War (see Erratic Test) in which tests failed randomly as they try to use the same fixture resource at the same time as some other test.
We can avoid Unrepeatable Tests and Test Run Wars entirely if we set up the fixture each time the test suite is run. xUnit provides several ways to do this including Lazy Setup (page X), SuiteFixture Setup (page X) and Setup Decorator (page X). The concept of "lazy initialization" should be familiar to most object-oriented developers; we just apply the concept to the construction of the test fixture. The latter two choices provide a way to tear down the test fixture when the test run is finished because they call a setUp method and a corresponding tearDown at the appropriate times; Lazy Setup does not give us a way to do this.
Chained Tests is another option for setting up a Shared Fixture, one that involves running the tests in a predefined order and letting each test use the previous tests results as its test fixture. Unfortunately, once one test fails, many of the tests that follow will provide erratic results because their preconditions have not been satisfied. This can be made easier to diagnose by having each test use Guard Assertions (page X) to verify that their preconditions have been met.(Unfortunately, this may result in slower tests when the fixture is in a database but it will still be many times faster than if each test had to insert all the records it needed.)
I have already mentioned Immutable Shared Fixture as a strategy for speeding up tests that use a Fresh Fixture. We can also use it to make tests based on a Shared Fixture less erratic by restricting changes to a smaller, mutable part Shared Fixture.
How Do We Ensure Testability?
The last strategic concern I touch on in this chapter is ensuring testability. I don't claim that this is a complete treatment of the topic because it is too large to cover in a chapter on test strategy. I don't, however, want to sweep it under the carpet either because it definitely has a large impact. But first, I must climb onto my soapbox for a short digression into development process.
Test Last - at Your Peril
Anyone who has tried to retrofit unit tests onto an existing application has probably experienced a lot of pain! This is the hardest kind of test automation we can do and the least productive as well. A lot of the benefit of the automated tests is derived during the "debugging phase" of software development by reduce the amount of time spent in debugging tools. Tackling a test retrofit on legacy software as your first attempt at automated unit testing is the last thing you want to try to do as it is sure to discourage even the most determined developers and project managers.
Design for Testability - Upfront
BDUF("Big Design, Up Front", also known as "waterfall design", is the opposite of emergent design or "just-in-time design".) design for testability is hard because it is hard to know what the tests will need in the way of control points and observation points on the SUT. We can easily build software that is difficult to test. We can also spend a lot of time designing in testability mechanisms that are either insufficient or unnecessary. Either way, we have spent a lot of effort with nothing to show for it.
Test-Driven Testability
The nice thing about building our software driven by tests is that we don't have to think very much about design for testability; we just write the tests and that forces us to build for testability. The act of writing the test defines the control points and observation points that the SUT needs to provide. Once we have passed the tests, we know we have a testable design.
Now that I've done my bit promoting TDD as a "Design for Testability" process , let's get on with discussing the mechanics of how we actually make our software testable.
Control Points and Observation Points
A test interacts with the software(I am deliberately not saying SUT because it interacts with more than just the SUT.) through one or more interfaces or interaction points. From the test's point of view these interfaces can act as either control points or observation points. A control point is how the test asks the software to do something for it. This could be for the purpose of putting the software into a specific state as part of setting up or tearing down the test fixture or it could be to exercise the SUT. Some control points are provided strictly for the tests; they should not be used by the production code because they bypass input validation or short-circuit the normal life-cycle of the SUT or some object on which it depends.
An observation points is how the test finds out about the SUT's behavior during the result verification phase of the test. Observation points can be used to retrieve the post-test state of the SUT or a DOC. They can also be used to spy on the interactions between the SUT and any components with which it is expected to interact while it is being exercised. Verifying these indirect outputs is an example of Back Door Verification (see Back Door Manipulation).
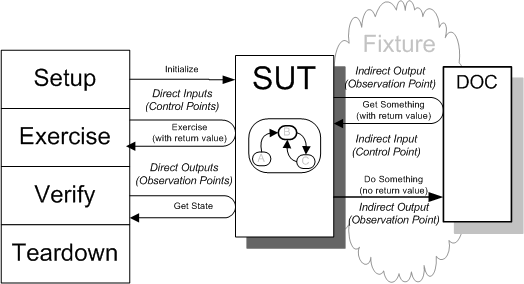
Sketch Interaction Points embedded from Interaction Points.gif
Fig. X: Control Points and Observation Points
The test interacts with the SUT through interaction points. Direct interaction points are synchronous method calls made by the test; indirect interaction points require some form of Back Door Manipulation. Control points have arrows pointing toward the SUT; observation points have arrows pointing away from the SUT.
Both control points and observation points can be provided by the SUT as synchronous method calls; we call this "going in the front door." Some interaction points may be via a "back door" to the SUT; we call this Back Door Manipulation. In the diagrams that follow, control points are represented by the arrowheads that point to the SUT whether from the test or from a DOC. Observation points are represented by the arrows whos heads point back to the test itself. These arrows typically start at the SUT or DOC(an asynchronous observation point.) or start at the test and interact with either the SUT or DOC before returning to the test(a synchronous observation point.).
Interaction Styles and Testability Patterns
When testing a particular piece of software, our tests can take one of two basic forms. A round trip test interacts with the SUT in question through its public interface; its "front door". Both the control points and the observation points in a typical round trip tests are simple method calls. The nice thing about this approach is that it does not violate encapsulation. The test only needs to know the public interface of the software; it doesn't need to know anything about how it is built.
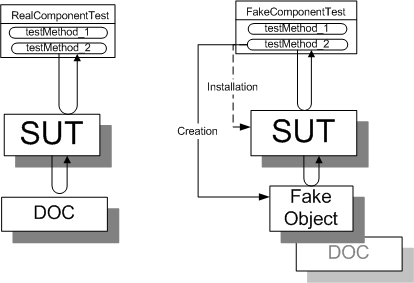
Sketch Round Trip Test embedded from Round Trip Test.gif
Fig. X: A round trip test interacts with the SUT only via the front door.
The test on the right replaces a DOC with a Fake Object to improve its repeatability or performance.
The main alternative is the layer-crossing test where we exercise the SUT through the API and keep an eye on what comes out the back using some form of Test Double such as a Test Spy (page X) or a Mock Object. This can be a very powerful testing technique for verifying certain kinds of mostly architectural requirements but it can also result in Overspecified Software (see Fragile Test) if overused because changes to how the software implements its responsibilities can cause tests to fail.
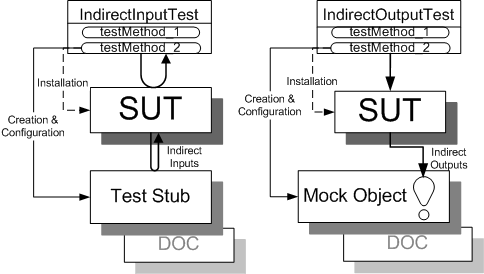
Sketch Layer Crossing Test embedded from Layer Crossing Test.gif
Fig. X: A layer-crossing test can interact with the SUT via a "back door".
The test on the left controls the SUT's's indirect inputs via a Test Stub while the test on the right verifies its indirect outputs using a Mock Object.
In the figure above, the test on the left is using a Mock Object that is standing in for the DOC as the observation point. The test on the right is using a Test Stub that is standing in for the DOC as a control point. Testing in this style implies a Layered Architecture[DDD,PEAA,WWW] and that opens up the door to using Layer Tests (page X) to test each layer of the architecture independently. An even more general concept is the use of Component Tests (see Layer Test) to test each component within a layer independently.
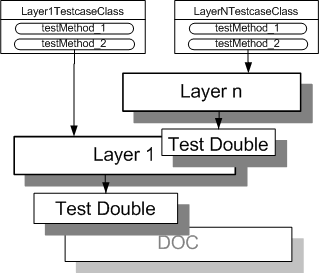
Sketch Layer Tests embedded from Layer Tests.gif
Fig. X: A pair of Layer Tests each testing a different layer of the system.
Each layer of a Layered Architecture can be tested independently using a distinct set of Layer Tests. This ensures good separation of concerns and the tests reinforce the Layered Architecture.
Whenever we want to write layer-crossing tests, we need to ensure that we have built in a substitutable dependency mechanism for any components the SUT depends on that we want to test independently of. The leading contenders are one of the variations of Dependency Injection or some form of Dependency Lookup such as Object Factory or Service Locator. These can be hand-coded or we can use an "inversion of control" framework if one is available in our programming environment. The fallback plan is using a Test-Specific Subclass (page X) of the SUT or the DOC in question. It can be used to override the dependency access or construction mechanism within the SUT or to replace the behavior of the DOC with test-specific behavior. The absolute "solution of last resort" is the Test Hook (page X)(These typically take the form of if (testing) then ... else ... endif.). These do have a use as a temporary measure to allow us to retrofit tests specifically to act as a Safety Net (see Goals of Test Automation) while refactoring but we definitely shouldn't make a habit of it as it will result in Test Logic in Production (page X).
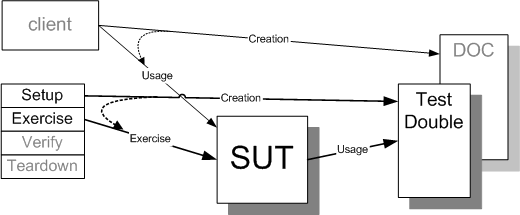
Sketch Dependency Injection embedded from Dependency Injection.gif
Fig. X: A Test Double being "injected" into a SUT by a test.
Dependency Injection is one technique a test can use to replace a DOC with an appropriate Test Double. The DOC is passed to the SUT by the test as or after it has been created.
A third kind of test worth talking about is the asynchronous test where the test interacts with the SUT through real messaging. Because the responses to these requests also come asynchronously, these tests must include some kind of interprocess synchronization such as calls to wait. Unfortunately, the need to wait long enough for message responses that don't ever come can cause these tests to take much, much longer to execute. This style of testing should be avoided at all costs in unit and component tests. Fortunately, the Humble Executable (see Humble Object on page X) pattern can remove the need to conduct unit tests this way. It involves putting the logic that handles the incoming message into a separate class or component that can be tested synchronously using either a "round trip" or "layer crossing" style.
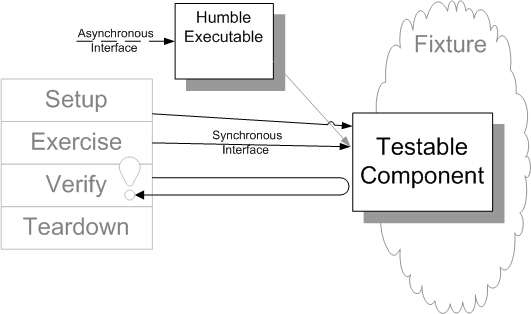
Sketch Humble Executable embedded from Humble Executable.gif
Fig. X: A Humble Executable making testing easier.
The Humble Executable pattern can be used to improve the repeatability and speed of verifying logic that would otherwise have to be verified via asynchronous tests.
A related issue is the testing of business logic through a user interface. In general, this Indirect Testing (see Obscure Test) is a bad idea because changes to the UI code will break tests that are trying to verify the business logic behind it. Since the UI tends to change a fair bit, especially on agile projects, this will greatly increase test maintenance costs. The other reason this is a bad idea is that user interfaces are inherently asynchronous. Tests that exercise the system through the user interface have to be asynchronous tests with all the issues that come with them.
Divide and Test
We can turn almost any Hard-to-Test Code (page X) into easily tested code through refactoring as long as we have enough tests in place to ensure we do not introduce bugs during this refactoring.
We can avoid using the UI for customer tests by writing them as Subcutaneous Tests (see Layer Test). These tests bypass the user interface layer of the system to exercise the business logic via a Service Facade[CJ2EEP] that exposes the necessary synchronous interaction points to the test. The user interface uses the same facade so we can verify that the business logic works correctly even before we hook up the user interface logic. The Layered Architecture also enables us to test the user interface logic before the business logic is finished; we can replace the Service Facade with a Test Double that provides completely deterministic behavior that our tests can depend on. (This can either be hard-coded or file driven but either way it should be independent of the real implementation so that the UI tests only need to know what data to use to evoke specific behaviors from the Service Facade, not the logic behind it.)
When unit testing non-trivial user interfaces (Any UI that contains state or conditional display or enabling of elements should be considered non-trivial.) we can use a Humble Dialog (see Humble Object) to move the logic that makes decisions about the user interface out of the visual layer, which is hard to test synchronously, into a layer of supporting objects that can be tested with standard unit testing techniques. This allows the presentation logic behavior to be just as well tested as the business logic behavior.
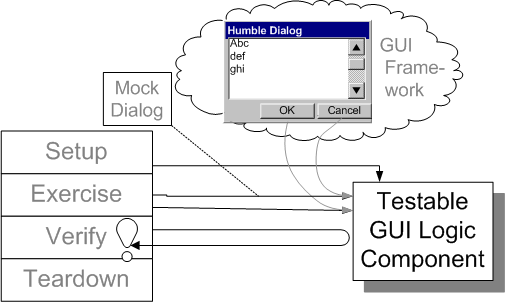
Sketch Humble Dialog embedded from Humble Dialog.gif
Fig. X: A Humble Dialog reducing the dependency of the test on the UI framework.
The logic that controls the state of user interface components can be very hard to test; extracting it into a testable component leaves behind a Humble Dialog that requires very little testing.
From a test automation strategy perspective, the key thing is to make the decision about what test-SUT interaction styles should be used and which ones should be avoided and to ensure that the software is designed to support that decision.
What's Next?
This concludes our introduction to the hard-to-change decisions we must make as we settle upon our test automation strategy. Since you are still reading I am going to assume that you have decided that xUnit was an appropriate tool for doing your test automation. In the following chapters I introduce the detailed patterns for implementing our chosen fixture strategy whether it is a Fresh Fixture strategy or a Shared Fixture strategy. First, I will describe the simplest case, a Transient Fresh Fixture in the Transient Fixture Management narrative chapter. After that I will describe the use of persistent fixtures in the Persistent Fixture Management narrative chapter. But first, I must establish the basic xUnit terminology and notation that I use throughout this book in the XUnit Basics narrative chapter.
Copyright © 2003-2008 Gerard Meszaros all rights reserved