
Using Test Doubles
The book has now been published and the content of this chapter has likely changed substanstially.About This Chapter
The last few chapters concluding with the Result Verification narrative introduced the basic mechanisms of running tests using the xUnit family of Test Automation Frameworks (page X). For the most part we assumed that the system under test (SUT) was designed such that it could be tested easily in isolation of other pieces of software. When a class does not depend on any other classes testing it is pretty straight-forward and the techniques described in this chapter are unnecessary. When a class does depend on other classes, we have two choices. We can test it together with the all the other classes it depends on or we can try to isolate it from the other classes so that we can test it by itself. In this chapter I introduce techniques for isolating the SUT from the other software components on which it depends.
What are Indirect Inputs and Outputs?
The problem with testing classes in groups or clusters is that it becomes very hard to cover all the paths through the code. The depended-on component (DOC) may return values or throw exceptions that affect the behavior of the SUT but it may difficult or impossible to cause certain cases to occur. The indirect inputs received from the DOC may be unpredictable (such as the system clock or calendar). In other cases, the DOC may not be available in the test environment or may not even exist. How can we test in these circumstances?
In yet other cases, we need to verify that certain side-effects of executing the SUT have indeed occurred. If it is hard to monitor these indirect outputs of the SUT (or it is too expensive to retrieve them), the effectiveness of our automated testing may be compromised. As you will no doubt have guessed from the title of this chapter, the solution to all these problems is often the use of a Test Double (page X). We will start by looking at how we can use them to test indirect inputs and outputs and then we will describe a few other uses.
Why do we care about Indirect Inputs?
Calls to depended on components often return objects, values, or even throw exceptions. Many of the execution paths within the SUT are there to deal with these different return values and to handle the various possible exceptions. Leaving these paths untested is an example of Untested Code (see Production Bugs on page X). These paths can be the hardest to test effectively but they are also among the most likely to lead to failures.
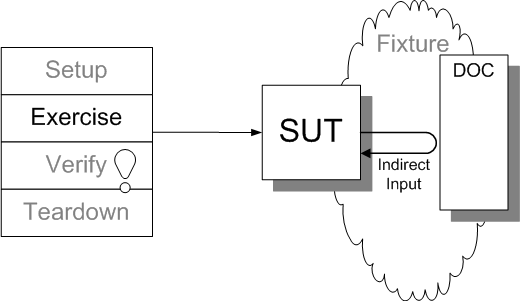
Sketch Indirect Input embedded from Indirect Input.gif
Fig. X: An indirect input being received by the SUT from a DOC.
Not all inputs of the SUT come from the test; some indirect inputs come from other components called by the SUT in the form of return values, updated parameters or exceptions thrown.
We certainly would rather not have the exception handling code executed for the first time in production. What if it was coded incorrectly? Clearly, it would be highly desirable to have automated tests for such code. The testing challenge is to somehow cause the DOC to throw an exception so that the error path can be tested. The exception we expect the DOC to throw is a good example of an indirect input test condition. Our means of injecting this input is a control point.
Why do we care about Indirect Outputs?
The concept of encapsulation often directs us to not care about how something is implemented. After all, that is the whole purpose of encapsulation--to alleviate the need for clients of our interface to care about our implementation. When testing, we are trying to verify the implementation precisely so our clients do not have to care about it.
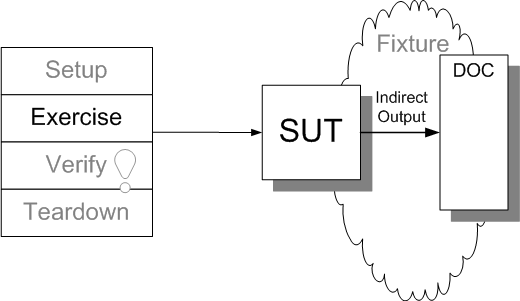
Sketch Indirect Output embedded from Indirect Output.gif
Fig. X: An indirect output being received by the SUT.
Not all outputs of the SUT are directly visible to the test; some indirect outputs are sent to other components in the form of method calls or messages.
Consider for a moment a component that has an API but one which returns nothing or at least nothing that can be used to determine whether it has performed its function correctly? This is a situation in which we have no choice but to test through the back door. A good example of this is a message logging system. Calls to the API of a logger rarely return anything that indicates it did its job correctly. The only way to determine whether it is working as expected is to interact with it through some other interface, one that allows us to retrieve the logged messages.
Clients of the logger may have requirements to call the logger when certain conditions are met. These calls will not be visible on the clients interface but would typically be a requirement that the client needs to satisfy and therefore something we want to test. The circumstances that should result in a messaging being logged are indirect output test conditions for which we need to write tests if we want to avoid having Untested Requirements (see Production Bugs). Our means of seeing this output is an observation point.
In other cases, the SUT does have visible behavior that can be verified through the front door but also has some expected "side-effects". Both need to be verified in our tests. Sometimes it is simply a matter of adding assertions for the indirect outputs to the existing tests to verify the Untested Requirement.
How do we control Indirect Inputs?
Testing with indirect inputs is a bit simpler than testing indirect outputs because the techniques for outputs build on the techniques for inputs. So let us delve into indirect inputs first. To test the SUT with indirect inputs, we must be able to control the depended-on component well enough to cause it to return every possible kind of return value. That implies the availability of a suitable control point.
Examples of the kinds of indirect inputs we want to be able to induce via this control point include:
- return values of methods/functions
- values of updatable arguments
- exceptions that could be thrown
In many cases, the test can interact with the depended-on component to set up how it will respond to requests. For example, if a component provides data access then it is possible to use Back Door Setup (see Back Door Manipulation on page X) to insert specific values into a database to cause the component to respond in the desired ways (no items found, one item found, many items found, etc.) In this specific case it is possible to use the database itself as a control point.
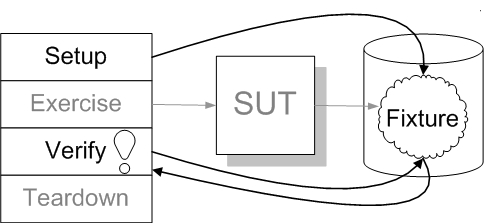
Sketch Back Door Manipulation embedded from Back Door Manipulation.gif
Fig. X: Using Back Door Manipulation to indirectly control and observe the SUT.
When the SUT stores its state in another component we may be able to manipulate its state by by having the test interact directly with the other component via a "back door".
In most cases, however, it is not practical or even possible. Reasons why we might not be able to use the real component include:
- The real component cannot be caused to make the desired indirect input occur. Only a true software error within the real component would result in the desired input to the SUT.
- The real component could be caused to make the input occur but the cost or complexity of doing so would make using it not cost effective.
- The real component could be caused to make the input occur but doing so could have unacceptable side effects.
So if the real component cannot be used as a control point we have to replace it with one that we can control. This replacement can be be done a number of different ways, which is the topic of discussion in Installing The Test Double later in this chapter. The most common approach is to configure a Test Stub (page X) with a set of values to return from its functions and install it into the SUT. During execution of the SUT, the Test Stub receives the calls and returns the previously configured responses. It has become our control point.
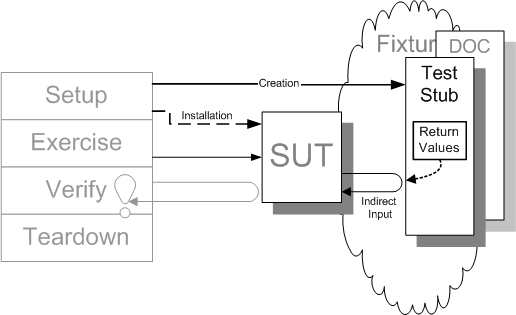
Sketch Test Stub embedded from Test Stub.gif
Fig. X: Using a Test Stub as a control point for indirect inputs.
One way to use a control point to inject indirect inputs into the SUT is to install a Test Stub in place of the DOC. Before exercising the SUT we tell the Test Stub what it should return to the SUT when it is called. This allows us to force the SUT through all its code paths.
How do we verify Indirect Outputs?
In normal usage, as the SUT is exercised, it interacts naturally with the component(s) upon which it depends. To test the indirect outputs, we must be able to observe the calls that the SUT makes to the API of the depended-on component. Furthermore, if we need the test to progress beyond that point, we also need to be able to control the values returned (as was discussed in the discussion of indirect inputs.)
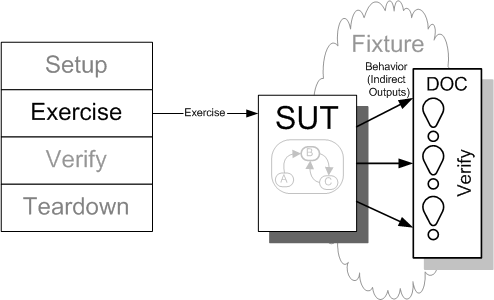
Sketch Behavior Verification embedded from Behavior Verification.gif
Fig. X: Using Behavior Verification (page X) to verify the indirect outputs of the SUT.
When we care about exactly what calls our SUT makes to other components, we may have to do Behavior Verification rather than be content with verifying the post-test state of the SUT.
In many cases, the test can use the depended-on component as an observation point to find out how it has been used. Examples include:
- Asking the file system for the contents of a file that the SUT has written to verify that it exists and was written with the expected contents.
- Asking the database for the contents of a table or specific record to verify that the SUT wrote the expected records to the database.
- Interacting directly with the e-mail sending component to ask whether the SUT had asked it to send a particular e-mail.
Some DOCs allow us to configure their behavior in such a way that we can use them to keep the test informed of how they are being used.
- Asking the file system to notify the test whenever a file is created or modified so we can verify its contents.
- Using a database trigger to notify the test when a record is written or deleted.
- Configuring the e-mail sending component to deliver all outgoing e-mail to the test.
In many cases, and as we have seen with indirect inputs, it is not practical to use the real component as an observation point. When all else fails, we may need to replace the real component with a test-specific alternative. Reasons why we might need to do this include:
- The calls to (or the internal state of) the depended-on component cannot be queried.
- The real component can be queried but the cost or complexity of doing so makes using it cost prohibitive.
- The real component can be queried but using so has unacceptable side effects.
The replacement of the real component can be be done a number of different ways which will be covered in Installing The Test Double.
There are two basic styles of indirect output verification. Procedural Behavior Verification (see Behavior Verification) involves capturing the calls (or their results) to a depended-on component during SUT execution and then comparing them with the expected calls after the SUT has finished executing. This is done by replacing a substitutable dependency with a Test Spy (page X). During execution of the SUT, the Test Spy receives the calls and records them. After the Test Method (page X) has finished exercising the SUT, it retrieves the actual calls from the Test Spy and uses Assertion Methods (page X) to compare them with the expected calls.
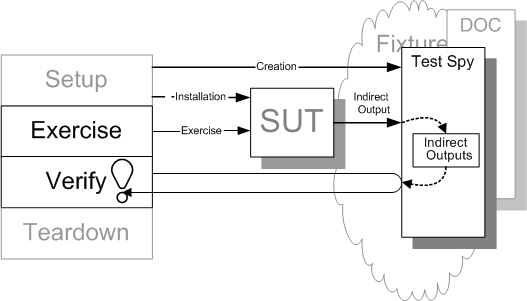
Sketch Test Spy embedded from Test Spy.gif
Fig. X: Using a Test Spy as an observation point for indirect outputs of the SUT.
One way to implement Behavior Verification is to install a Test Spy in place of the target of the indirect outputs. After exercising the SUT the test can ask the Test Spy for information about how it was used and compare it to the expected behavior using assertions.
Expected Behavior (see Behavior Verification) involves building a "behavior specification" during the fixture setup phase of the test and then comparing the actual behavior with this Expected Behavior. This is typically done by loading a Mock Object (page X) with a set of expected procedure call descriptions and installing it into the SUT. During execution of the SUT, the Mock Object receives the calls and compares them to the previously defined expected calls (the "behavior specification".) As the test proceeds, if the Mock Object receives an unexpected call, it fails the test immediately. The test failure trace back will show the exact location in the SUT where the problem occurred because the Assertion Methods are being called from the Mock Object which is in turn called by the SUT. We can also see exactly where in the Test Method the SUT was being exercised.
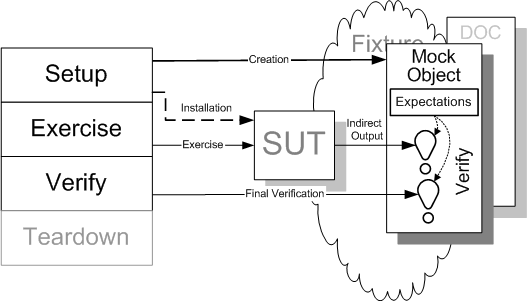
Sketch Mock Object embedded from Mock Object.gif
Fig. X: Using a Mock Object as an observation point for indirect outputs of the SUT.
Another way to implement Behavior Verification is to install a Mock Object in place of the target of the indirect outputs. As the SUT makes calls to the DOC, the Mock Object uses assertions. to compare them with the expected calls and arguments.
Whether we are using a Test Spy or a Mock Object, we may also have to use it as a control point for any indirect inputs that affect the test outcome.
Testing with Doubles
By now you are probably wondering about how to replace those inflexible and uncooperative real components with something that makes it easier to control indirect inputs and to verify indirect output.
As we have seen, to test the indirect inputs, we must be able to control the depended-on component well enough to cause it to return every possible kind of return value (valid, invalid, and exception). To test indirect outputs, we need to be able to track the calls the SUT makes to other components. A Test Double is a type of object that is much more cooperative and let us us write tests the way we want to.
Types of Test Doubles
A Test Double is any object or component that we install in place of the real component specifically so that we can run a test. Depending on the reason for why we are using it, it can behave in one of four basic ways:
- A Dummy Object (page X) is a placeholder object that is passed to the SUT as an argument (or an attribute of an argument) but is never actually used.
- A Test Stub is an object that is used by a test to replace a real component on which the SUT depends so that the test can control the indirect inputs of the SUT. This allows the test to force the SUT down paths it might not otherwise exercise. A more capable version of a Test Stub, the Test Spy can be used to verify the indirect outputs of the SUT by giving the test a way to inspect them after exercising the SUT.
- A Mock Object is an object that is used by a test to replace a real component on which the SUT depends so that the test can verify its indirect outputs.
- A Fake Object (page X) (or just "Fake" for short) is an object that replaces the functionality of the real depended-on component with an alternate implementation of the same functionality.
This is all summarized in the following diagram:
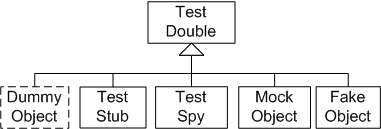
Sketch Types Of Test Doubles embedded from Types Of Test Doubles.gif
Fig. X: There are a number of different kinds of Test Doubles.
Dummy Objects are really an alternative to the Value Patterns. Test Stubs are used to verify indirect inputs; Test Spies and Mock Objects are used to verify indirect outputs.
Dummy Objects
Dummy Objects are a degenerate form of Test Double. They simply exist to be passed around from method to method and are never used. They are not expected to do anything except exist. Often, we can get away with using "null" (or "nil" or "nothing" ...) but sometimes we are forced to create a real object because the code expects something non-null. In dynamically typed languages, almost any real object will do; in statically typed languages we must make sure that the Dummy Object is "type-compatible" with the parameter it is being passed as or the variable to which it is being assigned. In this example we pass an instance of DummyCustomer to the Invoice constructor to satisfy a mandatory argument. We expect that the DummyCustomer will never actually be used by the code we are testing here.
public void testInvoice_addLineItem_DO() {
final int QUANTITY = 1;
Product product = new Product("Dummy Product Name", getUniqueNumber());
Invoice inv = new Invoice( new DummyCustomer() );
LineItem expItem = new LineItem(inv, product, QUANTITY);
// Exercise
inv.addItemQuantity(product, QUANTITY);
// Verify
List lineItems = inv.getLineItems();
assertEquals("number of items", lineItems.size(), 1);
LineItem actual = (LineItem)lineItems.get(0);
assertLineItemsEqual("", expItem, actual);
}
Example DummyObject embedded from java/com/clrstream/camug/example/test/InvoiceTest.java
Note that a Dummy Object is not the same as a Null Object[PLOPD3]. A Dummy Object is not used by the SUT so its behavior is irrelevant while a Null Object is used by the SUT but is designed to do nothing. A small but very important distinction!
Dummy Objects are in different league from the other Test Doubles; they are really an alternative to the attribute value patterns such as Literal Value (page X), Generated Value (page X) and Derived Value (page X). Therefore, we don't need to "configure" them or "install" them. In fact, almost nothing we say about the other Test Doubles applies to them so I won't mention them again in this chapter.
Test Stubs
A Test Stub is an object that acts as a control point to deliver indirect inputs to the SUT when the Test Stub's methods are called. This allows Untested Code paths in the SUT to be exercised that might otherwise be impossible to hit. A Responder (see Test Stub) is a basic Test Stub that is used to inject valid and invalid indirect inputs into the SUT via normal returns from method calls. A Saboteur (see Test Stub) is a special Test Stub that raises exceptions or errors to inject abnormal indirect inputs into the SUT. Because procedural programming languages do not support objects they force us to use Procedural Test Stubs (see Test Stub).
In the following example, the Saboteur throws an exception when the SUT calls the getTime method to allow us to verify that the SUT behaves correctly in this case.
public void testDisplayCurrentTime_exception() throws Exception {
// fixture setup
// Define and instantiate Test Stub
TimeProvider testStub = new TimeProvider()
{ // anonymous inner Test Stub
public Calendar getTime() throws TimeProviderEx {
throw new TimeProviderEx("Sample");
}
};
// Instantiate SUT:
TimeDisplay sut = new TimeDisplay();
sut.setTimeProvider(testStub);
// exercise sut
String result = sut.getCurrentTimeAsHtmlFragment();
// verify direct output
String expectedTimeString = "<span class=\"error\">Invalid Time</span>";
assertEquals("Exception", expectedTimeString, result);
}
Example ExceptionInputTest embedded from java/com/clrstream/ex7/test/TimeDisplayTestSolution.java
In procedural programming languages, a Procedural Test Stub is a either a Test Stub implemented as a stand-in for an as-yet unwritten procedure or an alternate implementation of a procedure linked into the program instead of the real implementation of the procedure. Traditionally, they are introduced to allow debugging to proceed while waiting for other code to be ready. It is rare for them to be "swapped in" at runtime because this is hard to do in most procedural languages. If we do not mind introducing Test Logic in Production (page X) code, we can implement a Procedural Test Stub using Test Hooks (page X) such as if testing then ... else in the SUT. The key exception to this is in languages that support procedure variables. (Also called function pointers.) These allow us to do dynamic binding as long as the client code accesses the procedure to be replaced via a procedure variable.
public Calendar getTime() throws TimeProviderEx {
Calendar theTime = new GregorianCalendar();
if (TESTING) {
theTime.set(Calendar.HOUR_OF_DAY, 0);
theTime.set(Calendar.MINUTE, 0);}
else {
// just return the calendar
}
return theTime;
};
Example TestHookInDOC embedded from java/com/xunitpatterns/dft/lookup/HookedTimeProvider.java
Test Spies
A Test Spy is an object that can act as an observation point for indirect outputs of the SUT. To the capabilities of a Test Stub it adds the capability to quietly record all the calls made to its methods by the SUT. In the verification part of the test, the test perform Procedural Behavior Verification on those calls by comparing the actual calls received by the Test Spy with the expected calls using a series of assertions. This next example uses the Retrieval Interface (see Test Spy) on the Test Spy to verify that the correct information was passed as arguments to the call to logMessage method by the SUT (the removeFlight method of the facade.)
public void testRemoveFlightLogging_recordingTestStub() throws Exception {
// fixture setup
FlightDto expectedFlightDto = createAnUnregFlight();
FlightManagementFacade facade = new FlightManagementFacadeImpl();
// Test Double setup
AuditLogSpy logSpy = new AuditLogSpy();
facade.setAuditLog(logSpy);
// exercise
facade.removeFlight(expectedFlightDto.getFlightNumber());
// verify
assertFalse("flight still exists after being removed",
facade.flightExists( expectedFlightDto.getFlightNumber()));
assertEquals("number of calls", 1, logSpy.getNumberOfCalls());
assertEquals("action code", Helper.REMOVE_FLIGHT_ACTION_CODE,
logSpy.getActionCode());
assertEquals("date", helper.getTodaysDateWithoutTime(), logSpy.getDate());
assertEquals("user", Helper.TEST_USER_NAME, logSpy.getUser());
assertEquals("detail", expectedFlightDto.getFlightNumber(),
logSpy.getDetail());
}
Example RecordingTestStubUsage embedded from java/com/clrstream/ex8/test/FlightManagementFacadeTestSolution.java
Mock Objects
A Mock Object is also an object that can act as an observation point for indirect outputs of the SUT. Like a Test Stub, it may need to return information in response the method calls. Like a Test Spy, it pays attention to how it was called by the SUT. Where it differs from a Test Spy is that the Mock Object is the one who compares actual calls received with the previously defined expectations using assertions and fails the test on behalf of the Test Method. This makes it possible to reuse the logic used to verify the indirect outputs of the SUT across all the tests that use the same Mock Object. Mock Objects come in two basic flavors:
- A strict Mock Object fails the test if the correct calls are received in a different order than was specified.
- A lenient(Lenient Mock Objects are sometimes called "nice" but this seems less evocative to me.) Mock Object tolerates out-of-order calls and sometimes unexpected calls or missed calls. That is, it may only verify the actual calls that correspond to expected ones.
The following test configures a Mock Object with the arguments of the expected call to logMessage. When the SUT (the removeFlight method) calls logMessage, the Mock Object will assert that each of the actual arguments equals the expected arguments. If any wrong arguments are passed, the test fails.
public void testRemoveFlight_Mock() throws Exception {
// fixture setup
FlightDto expectedFlightDto = createAnonRegFlight();
// mock configuration
ConfigurableMockAuditLog mockLog = new ConfigurableMockAuditLog();
mockLog.setExpectedLogMessage( helper.getTodaysDateWithoutTime(),
Helper.TEST_USER_NAME,
Helper.REMOVE_FLIGHT_ACTION_CODE,
expectedFlightDto.getFlightNumber());
mockLog.setExpectedNumberCalls(1);
// mock installation
FlightManagementFacade facade = new FlightManagementFacadeImpl();
facade.setAuditLog(mockLog);
// exercise
facade.removeFlight(expectedFlightDto.getFlightNumber());
// verify
assertFalse("flight still exists after being removed",
facade.flightExists( expectedFlightDto.getFlightNumber()));
mockLog.verify();
}
Example ActiveMockObject embedded from java/com/clrstream/ex8/test/FlightManagementFacadeTestSolution.java
Mock Objects often include the capability of Test Stubs to be configured with any indirect inputs required to allow the SUT to advance to the point where it would generate the indirect outputs they are verifying.
Fake Objects
A Fake Object (or just "Fake" for short) is quite different from a Test Stub or a Mock Object in that it is neither directly controlled nor observed by the test. It is an object that replaces the functionality of the real depended-on component in a test for reasons other than verification of indirect inputs and outputs. Typically, it will implement the same or a subset of the functionality of the real depended-on component but in a much simpler way. The most common reason for using one is that the real depended-on component is not available yet, is too slow or is not available in the test environment. the sidebar Faster Tests Without Shared Fixtures (page X) describes how we encapsulated all database access behind a persistence layer interface and them dummied them out with hash tables and made our tests run 50 times faster using a Fake Database (see Fake Object) something like this one:
public class InMemoryDatabase implements FlightDao{
private List airports = new Vector();
public Airport createAirport(String airportCode, String name, String nearbyCity)
throws DataException, InvalidArgumentException {|-------10--------20--------30--------40--------50--------60-----|
assertParamtersAreValid( airportCode, name, nearbyCity);
assertAirportDoesntExist( airportCode);
Airport result = new Airport(getNextAirportId(),
airportCode, name, createCity(nearbyCity));
airports.add(result);
return result;
}
public Airport getAirportByPrimaryKey(BigDecimal airportId)
throws DataException, InvalidArgumentException {
assertAirportNotNull(airportId);
Airport result = null;
Iterator i = airports.iterator();
while (i.hasNext()) {
Airport airport = (Airport) i.next();
if (airport.getId().equals(airportId)) {
return airport;
}
}
throw new DataException("Airport not found:"+airportId);
}
Example FakeDatabase embedded from java/com/clrstream/ex6/persistence/InMemoryDatabase.java
Providing the Test Double
There are two approaches to providing a Test Double. A Hand-Built Test Double (see Configurable Test Double on page X) is coded by the test automater while a Dynamically Generated Test Double (see Configurable Test Double) is generated at run time using a framework or toolkit provided by some other developer(s)(JMock and its ports to other languages are a good examples of such toolkits. Other toolkits, such as EasyMock, implement Statically Generated Test Doubles (see Configurable Test Double) by generating code that is then compiled just like a Hand-Built Test Double.). All generated Test Doubles need to be, by their very nature, Configurable Test Doubles and they will be covered in more detail in the next section. Hand-Built Test Doubles on the other hand tend to be Hard-Coded Test Doubles (page X) although they can also be made configurable at some additional effort. The following code sample illustrates a hand-coded Inner Test Double (see Hard-Coded Test Double) using Java's anonymous inner class construct:
public void testDisplayCurrentTime_AtMidnight_PS() throws Exception {
// fixture setup
// Define and instantiate Test Stub
TimeProvider testStub = new PseudoTimeProvider()
{ // anonymous inner stub
public Calendar getTime(String timeZone) {
Calendar myTime = new GregorianCalendar();
myTime.set(Calendar.MINUTE, 0);
myTime.set(Calendar.HOUR_OF_DAY, 0);
return myTime;
}
};
// Instantiate SUT:
TimeDisplay sut = new TimeDisplay();
// Inject Test Stub into SUT:
sut.setTimeProvider(testStub);
// exercise sut
String result = sut.getCurrentTimeAsHtmlFragment();
// verify direct output
String expectedTimeString = "<span class=\"tinyBoldText\">Midnight</span>";
assertEquals("Midnight", expectedTimeString, result);
}
Example PseudoClassBasedInnerStub embedded from java/com/clrstream/ex7/test/TimeDisplayTestSolution.java
We can greatly simplify the development of Hand-Built Test Doubles in statically typed languages such as Java and C# by providing a set of base classes called Pseudo Objects (see Hard-Coded Test Double) from which to subclass. This can reduce the number of methods we need to implement in each Test Stub, Test Spy or Mock Object to just the ones we expect to be called. They are especially helpful when using Inner Test Doubles or Self Shunts (see Hard-Coded Test Double). The class definition for the Pseudo Object used in the previous example looks like this:
/**
* Base class for hand-coded Test Stubs and Mock Objects
*/
public class PseudoTimeProvider implements ComplexTimeProvider {
public Calendar getTime() throws TimeProviderEx {
throw new PseudoClassException();
}
public Calendar getTimeDifference(Calendar baseTime, Calendar otherTime)
throws TimeProviderEx {
throw new PseudoClassException();
}
public Calendar getTime( String timeZone ) throws TimeProviderEx {
throw new PseudoClassException();
}
}
Example PseudoClass embedded from java/com/clrstream/ex7/test/PseudoTimeProvider.java
Configuring the Test Double
Some Test Doubles (specifically Test Stubs and Mock Objects) need to be told what values to return and/or what values to expect. A Hard-Coded Test Double is told at design time by the test automater while a Configurable Test Double is told at run-time by the test. A Test Stub or a Test Spy only needs to be programmed with the values to be returned by the methods we expect the SUT to invoke. A Mock Object also needs to be programmed with the names and arguments of all the methods we expect the SUT to invoke on it. In all cases it is the test automater who ultimately decides with what values to program the Test Double so the primary considerations in the decision are the understandability of the test and reuse of the Test Double code.
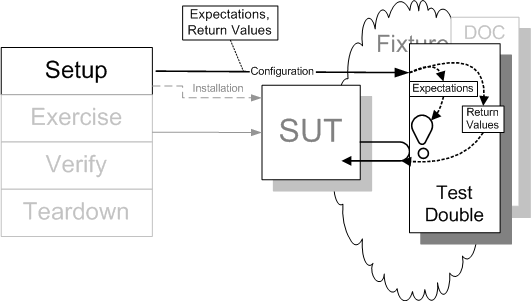
Sketch Configurable Test Double embedded from Configurable Test Double.gif
Fig. X: A Test Double being configured by the test.
We can avoid a proliferation of Hard-Coded Test Doubles classes by passing return values or expectation to the Configurable Test Double at runtime.
Fake Objects do not need to be "configured" at run-time because they are just used by the SUT and later outputs depend on the earlier calls by the SUT. Similarly, Dummy Objects do not need to be "configured" because they should never be executed(Dummy Objects can be used as an observation point to verify that it was never used by ensuring it throws an exception if any of its methods are called.). Procedural Test Stubs are typically built as Hard-Coded Test Doubles. That is, they are hard-coded to return a particular value when the function is called. This is the simplest form of test double.
A Configurable Test Double can provide either a Configuration Interface (see Configurable Test Double), or a Configuration Mode (see Configurable Test Double) that the test can use to program the Test Double with the values to return or expect. This makes these Configurable Test Double reusable across many tests. It also makes the test more understandable by making the values used by the Test Double visible within the test thus avoiding the smell of a Mystery Guest (see Obscure Test on page X).
So where should all this programming be done? The installation of the test double should be treated just like any other part of fixture setup. Alternatives such as Inline Setup (page X), Implicit Setup (page X) and Delegated Setup (page X) all apply.
Installing The Test Double
Before we exercise the SUT, we need to "install" any Test Doubles on which our test depends. I use the term "install" as a generic way to describe the process of telling the SUT to use our Test Double regardless of how we do it. The normal sequence is to instantiate the double, configure it if is a Configurable Test Double and then tell the SUT to use it either before or as we exercise the SUT. There are several distinct ways to "install" the Test Double and the choice between them may be as much a matter of style as necessity if we are designing the SUT for testability. Our choices may be much more constrained when retrofitting tests to an existing design.
The basic choices boil down to Dependency Injection (page X) in which the client software tells the SUT which DOC to use, Dependency Lookup (page X) in which the SUT delegates the construction or retrieval of the DOC to another object and Test Hook in which either the DOC, or the calls to it, are modified.
If an inversion of control framework is available in our language, using it allows dependencies to be substituted by tests without much additional work. This removes the need for building in the Dependency Injection or Dependency Lookup mechanism.
Dependency Injection
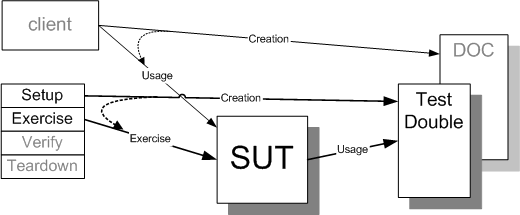
Sketch Dependency Injection embedded from Dependency Injection.gif
Fig. X: A Test Double being "injected" into the SUT by a test.
Using Test Doubles requires a means to replace the DOC; Dependency Injections involves having the caller supply the dependency to the SUT before or as it is used.
Dependency Injection is a class of design decoupling that involves having the client of the SUT tell the SUT what DOC to use at run time. It has been made popular by the test-driven development movement because it makes designs more easily tested. It also makes it possible to reuse the SUT more broadly because it removes knowledge of the dependency from the SUT; often the SUT will only be aware of a generic interface that the DOC must implement. Dependency Injection comes in several specific flavors; the choice between them is largely a matter of taste:
- Setter Injection (see Dependency Injection) -- The SUT accesses the DOC through a public attribute (i.e., a variable or property). The test explicitly sets the attribute after instantiating the SUT to installing the Test Double. The SUT may have previously initialized the attribute with the real DOC in its constructor (in which case the test is replacing it) or the SUT may use Lazy Initialization[SBPP] to initialize the attribute in which case the SUT will never bother to install the real DOC.
- Constructor Injection (see Dependency Injection) -- The SUT access the DOC through a private attribute. The test passes the Test Double to the SUT via a constructor that takes the DOC to be used as an explicit argument and initializes the attribute from it. This may be the primary constructor used by production code clients or it may be an alternate constructor. In the latter case, the primary constructor should call this constructor passing in the default DOC.
- Parameter Injection (see Dependency Injection) -- The SUT access the DOC through a method parameter; the test passes in a Test Double while production code passes in the real object. (This is the approach advocated in the original paper on Mock Object [ET]. In this paper, mocks passed as parameters to methods are called "Smart Handlers".) This approach works fine when the API of the SUT takes as a parameter the object we need to mock out. Although Mock Object aficionados argue that designing our APIs this way improves the design of the SUT, it is not always possible or practical to pass everything required to each method.
Dependency Lookup
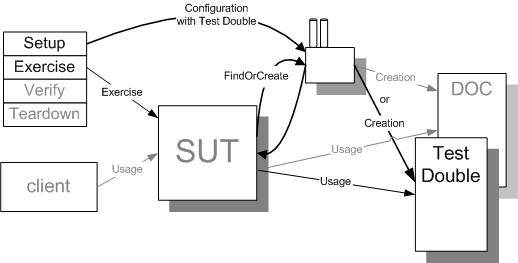
Sketch Dependency Lookup embedded from Dependency Lookup.gif
Fig. X: A Service Locator (see Dependency Lookup) being "configured" by a test to return a Test Double to the SUT.
Using Test Doubles requires a means to replace the DOC; Dependency Lookups involves having the SUT ask a well-known object to provide a reference to the DOC; the test can provide the Service Locator with a Test Double to return.
When software is not designed for testability or when Dependency Injection is not appropriate, we may find it convenient to use Dependency Lookup. This also removes the knowledge of exactly which DOC should be used from the SUT but it does so by having the SUT ask another piece of software to create or find the DOC on its behalf. This opens the door to changing the DOC at runtime without modifying the code of the SUT. We do have to modify the behavior of the intermediary somehow and this is where the specific variants differ:
- Object Factory (see Dependency Lookup) -- The SUT creates the DOC by calling a Factory Method[GOF] on a well-known object. The factory is designed so that it can be told what class to instantiate for a specific type of request. The test explicitly tells the factory to create a Test Double instead of a normal DOC.
- Service Locator -- The SUT retrieves a previously created service object by asking a well-known Registry[PEAA] object for it. The test tells the Service Locator to return the Test Double when the SUT requests an object. If the Service Locator has hard-coded behavior, we may be forced to use a Substitutable Singleton (see Test-Specific Subclass on page X) to implement the override mechanism.
The use of Singletons[GOF] specifically to act as a Service Locator is acceptable though best avoided through the use of an IOC tool or Dependency Injection as these make the dependency of the test on the use of a Test Double more obvious. Singletons used for other purposes almost always cause us headaches when writing tests and should be avoided if at all possible.
Retrofitting Testability using a Test-Specific Subclass
Even when none of these mechanisms are built into the SUT, we may be able to retrofit them relatively easily by using a Test-Specific Subclass.
- We can subclass the SUT itself to add a Dependency Injection mechanism or to replace method implementations with test-specific behavior thereby turning the SUT into its own Subclassed Test Double (see Test-Specific Subclass). We can also override any logic used to access a DOC thereby making it possible to return a Test Double instead of the normal DOC without modifying the production code. The main prerequisite is that the SUT uses Self-Calls[WWW] to non-private methods of any functionality we need to override from the test. Small, single-purpose methods rule! The main drawback of this approach is that it is possible to accidently override parts of the behavior we are intending to test.
- We can subclass the DOC to insert test-specific behavior effectively turning it into a Subclassed Test Double. This is somewhat safer than subclassing the SUT because it avoids accidently overriding parts of the SUT that we are testing. The trick, however, is to get the SUT to use the Test-Specific Subclass instead of the DOC. In practice, this implies one of the Dependency Injection or Dependency Lookup techniques unless the DOC is a Singleton. When the SUT uses a Singleton by calling a static soleInstance method on a hard-coded class name, the test can cause the soleInstance method to return an instance of a Test Double by subclassing the Singleton class and initializing the real Singleton's soleInstance class variable to hold an instance of the Test Double. The returned Test Double may need to be a Subclassed Test Double if the type of the variable used to hold the Singleton's sole instance is hard-coded as the Singleton's class. This technique is often how we get a Service Locator to return a different service but it can be used directly without an intermediary Service Locator.
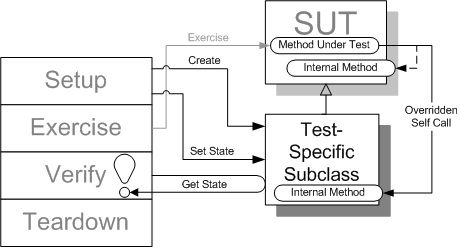
Sketch Test-Specific Subclass embedded from Test-Specific Subclass.gif
When all else fails, we can always try subclassing the SUT (or the DOC) to change or expose functionality we need to enable testing.
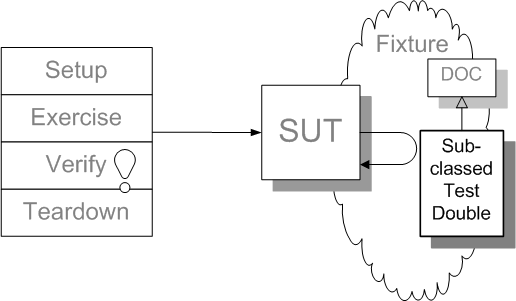
Sketch Subclassed Test Double embedded from Subclassed Test Double.gif
One way to build a Test Double is to subclass the real class and override the implementation of any methods we need to control the indirect inputs or verify indirect outputs.
Dependency Modification
This section could just as easily have been called "None of the above" because it is really a catch-all for techniques that involve neither injection nor delegation of the dependency.
- Test Hooks -- This is the "elephant in the room" that nobody wants to talk about because it may lead to Test Logic in Production. It is, however, a perfectly legitimate way to get legacy code under test when it is too hard or dangerous to introduce one of the techniques described above. It is best used as a transitionary strategy to allow Scripted Tests (page X) or Recorded Tests (page X) to be automated to provide a Safety Net (see Goals of Test Automation on page X) while large-scale refactoring is undertaken to improve testability. Ideally, once the code has been made more testable, better tests can be prepared using the techniques described earlier and the Test Hooks can be removed.
- Object Seams -- Michael Feathers describes in [WEwLC] several other techniques to replace dependencies with test-specific code under the general heading of finding "object seams". For example, we can replace a depended-on library with one designed specifically for testing. A seemingly hard-coded dependency can be broken this way. Most of these techniques are less applicable to dynamically replacing dependencies within individual tests than Dependency Injection or Dependency Lookup because they require changes to the environment. They are, however, an excellent way to get legacy code under test so that it can be refactored to introduce either of the above dependency-breaking techniques.
- Test PointCuts -- We can use Aspect-Oriented Programming (AOP) to install the Test Double behavior by defining a point-cut that matches only the place where we would install the Test Double. Note that while one needs an AOP-enabled development environment to do this, one does not need to deploy the AOP-generated code into a production environment. This makes it possible to use this technique even in AOP-hostile environments. I have not actually seen this used on projects and since there is limited literature available on it I will not claim it to be a pattern, yet.
Other Uses of Test Doubles
So far, we have covered the testing of indirect inputs and indirect outputs. Now let us look at some other uses of Test Doubles.
Endoscopic Testing
Tim Mackinnon et al introduced the concept of endoscopic testing [ET] in their initial Mock Objects paper. Endo-testing involves testing the SUT from the inside by passing in a Mock Object as an argument to the method under test. This allows verification of certain internal behaviors of the SUT that may not be at all visible from the outside.
The classic example they describe is the use of a mock collection class preloaded with all the expected members of the collection. When the SUT tries to add an unexpected member, the mock collection's assertion fails. This allows the full stack trace of the internal call stack to be visible in the JUnit failure report. If our IDE supports breaking on specified exceptions, we can also inspect the local variables at the point of failure.
Need-Driven Development
A refinement of "Endoscopic Testing" is "Need-driven development" [MRNO] in which the dependencies of the SUT are defined as the tests are written. This "outside-in" approach to writing and testing software combines the conceptual elegance of the old "top down" approach to writing code with the use of the modern techniques for test-driven development supported by Mock Objects. It allows us to build and test the software layer by layer starting at the outermost layer before we have implemented the lower layers.
Need-driven development combines the benefits of test-driven development (specifying all software with tests before we build them) with a highly incremental approach to design that removes the need for any speculation about how a depended-on class might be used.
Speeding Up Fixture Setup
Another use of Test Doubles is to reduce the runtime cost of Fresh Fixture (page X) setup. When the SUT needs to interact with other objects that are difficult to create because they have many dependencies, a single Test Double can be created instead of the complex network of objects. When applied to networks of entity objects, this technique is called Entity Chain Snipping (see Test Stub).
Speeding Up Test Execution
Another use of Test Doubles is to improve the speed of tests by replacing slow components with faster ones. Replacing a relational database with an in-memory Fake Object can reduce test execution times by an order of magnitude! The extra effort of coding the Fake Database is more than offset by the reduced waiting time and the quality improvement due to the more timely feedback that comes from running the tests more frequently. Refer to the sidebar Faster Tests Without Shared Fixtures for a more detailed discussion.
Other Considerations
Since many of our tests will involve replacing the real depended-on component with a Test Double, how do we know that it works properly when the real depended-on component is used? Of course, we would expect our customer tests to verify behavior with the real depended-on components in place (except, possibly, when the real depended-on components are interfaces to other systems that need to be stubbed out during single-system testing.) We should write a special form of Constructor Test (see Test Method), a "substitutable initialization test", to verify that the real depended-on component is installed properly. The trigger for writing this test is the first test that replaces the depended-on component with a Test Double since that is often when the Test Double installation mechanism is first introduced.
Finally, we want to be careful that we don't fall into the "new hammer trap" ("When you have a new hammer, everything looks like a nail".). Overuse of Test Doubles (and especially Mock Objects or Test Stubs) can lead to Overspecified Software (see Fragile Test on page X) by encoding implementation-specific information about the design in our tests. This can make it harder to change the design because many tests are impacted by the change only because they use a Test Double that has be affected by the design change.
What's Next?
In this chapter we have looked at techniques for testing software with indirect inputs and indirect outputs. I introduced the concept of Test Doubles and various techniques to installing them. Next, in the Organizing Our Tests narrative we will turn our attention to techniques for organizing our test code into Test Methods and Test Utility Methods (page X) living on Testcase Classes (page X) and Test Helpers (page X).
Copyright © 2003-2008 Gerard Meszaros all rights reserved